6 Erstellung von Tabellen und Abbildungen
Nach der Klärung der Grundlagen, die wichtig für die Arbeit mit R und Markdown sind, jedoch für manche Lesende etwas trocken sind, wird im Folgenden der Fokus auf die Erstellung von Tabellen und Abbildungen gelegt. Dazu werden neben den Basisfähigkeiten über die R von Haus aus verfügt, auch verschiedene Pakete (unter anderem flextable (Gohel 2021), ggplot2 (Wickham, Chang, et al. 2021) und ggrepel (Slowikowski 2021)) genutzt, die es ermöglichen auf einfachem Wege Tabellen und Abbildungen mit einem modernen Erscheinungsbild zu erzeugen, die für die Aufnahme in verschiedene Berichtsformate geeignet sind.
6.1 Erstellung einer Häufigkeitstabelle
Eine einfache Häufigkeitstabelle kann mit dem folgenden Befehl erzeugt werden:
table(dkf$D17_Schueler_Schulform_Lang)##
## Grundschule Gymnasium Sonderschule Stadtteilschule
## 5010 5208 4673 5109Die Tabelle zeigt an, wie sich die Schülerinnen und Schüler auf die verschiedenen Schulformen im Schuljahr 2017/18 verteilen und gibt die entsprechenden absoluten Zahlen wieder.
Um die zugehörigen Anteile zu erhalten, muss der Befehl wie folgt angepasst werden:
proportions(table(dkf$D17_Schueler_Schulform_Lang))##
## Grundschule Gymnasium Sonderschule Stadtteilschule
## 0.25050 0.26040 0.23365 0.25545Ebenso lassen sich Kreuztabellen erzeugen, indem im Befehl table() eine weitere Variable ergänzt wird, beispielsweise:
table(dkf$D17_Schueler_Schulform_Lang, dkf$D18_Schueler_Schulform_Lang)##
## Grundschule Gymnasium Sonderschule Stadtteilschule
## Grundschule 1257 1306 1198 1249
## Gymnasium 1297 1348 1306 1257
## Sonderschule 1216 1219 1062 1176
## Stadtteilschule 1298 1311 1136 1364Abermals können die entsprechenden Anteile mit dem Befehl proportions() ausgegeben werden:
proportions(table(dkf$D17_Schueler_Schulform_Lang, dkf$D18_Schueler_Schulform_Lang))##
## Grundschule Gymnasium Sonderschule Stadtteilschule
## Grundschule 0.06285 0.06530 0.05990 0.06245
## Gymnasium 0.06485 0.06740 0.06530 0.06285
## Sonderschule 0.06080 0.06095 0.05310 0.05880
## Stadtteilschule 0.06490 0.06555 0.05680 0.06820Den entsprechend geschulten Lesenden fällt dabei auf, dass aus den beiden erzeugten Kreuztabellen nicht hervorgeht, welche Variable in den Zeilen und welche Variable in den Spalten dargestellt ist. Auch wenn bei der Nutzung des Befehls table() grundsätzlich die erstgenannte Variable in den Zeilen und die zweitgenannte Variable in den Spalten dargestellt wird, wäre es vorteilhaft, wenn aus der Tabelle eindeutig hervorgehen würde, wo welche Variable dargestellt ist. Ebenso enthält die Tabelle keine Randverteilungen, sodass beispielsweise die Gesamtfallzahl nicht direkt ersichtlich ist.
addmargins(table(dkf$D17_Schueler_Schulform_Lang, dkf$D18_Schueler_Schulform_Lang))##
## Grundschule Gymnasium Sonderschule Stadtteilschule Sum
## Grundschule 1257 1306 1198 1249 5010
## Gymnasium 1297 1348 1306 1257 5208
## Sonderschule 1216 1219 1062 1176 4673
## Stadtteilschule 1298 1311 1136 1364 5109
## Sum 5068 5184 4702 5046 20000Dieser Befehl kann auch für die entsprechenden relativen Anteile verwendet werden:
addmargins(proportions(table(dkf$D17_Schueler_Schulform_Lang, dkf$D18_Schueler_Schulform_Lang)))##
## Grundschule Gymnasium Sonderschule Stadtteilschule Sum
## Grundschule 0.06285 0.06530 0.05990 0.06245 0.25050
## Gymnasium 0.06485 0.06740 0.06530 0.06285 0.26040
## Sonderschule 0.06080 0.06095 0.05310 0.05880 0.23365
## Stadtteilschule 0.06490 0.06555 0.05680 0.06820 0.25545
## Sum 0.25340 0.25920 0.23510 0.25230 1.00000Unabhängig von der zuvor verwendeten Variante – Häufigkeitstabelle oder Kreuztabelle, mit absoluten oder relativen Zahlen – ist auffällig, dass die erzeugten Ausgaben optisch nicht sonderlich ansprechend und kaum veröffentlichungsreif sind. Um eine veröffentlichungsreife Tabelle zu erzeugen, bietet sich das Paket flextable (Gohel 2021) an. Dieses ermöglicht Formatierungen an den erzeugten Tabellen vorzunehmen und diese in ein Berichtsformat aufzunehmen. Der Unterschied zu einer Tabelle, die über das base Paket erzeugt wurde, ist dass flextable einen Datenframe als erstes Objekt erwartet. Das bedeutet, die darzustellenden Daten sind zunächst in einen Datensatz zu überführen. In Kombination mit dem zuvor eingeführten dplyr Paket sowie dem Befehl pivot_wider() aus dem Paket tidyr (Wickham 2021) ist dies jedoch ein Leichtes.
table_sfo <- dkf %>%
group_by(D17_Schueler_Schulform_Lang, D18_Schueler_Schulform_Lang) %>%
summarize(n = n()) %>%
pivot_wider(names_from = D18_Schueler_Schulform_Lang, values_from = n)
flextable(table_sfo)D17_Schueler_Schulform_Lang | Grundschule | Gymnasium | Sonderschule | Stadtteilschule |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 |
Auf den ersten Blick ist ersichtlich, dass diese Ausgabe optisch ansprechender und eher die Kriterien einer veröffentlichungsreifen Tabelle erfüllt als die Standardanzeige einer Tabelle von R. Dennoch sind noch weitere Optimierungen vorzunehmen, um die Tabelle tatsächlich in einen Bericht aufnehmen zu können. Dazu zählen die Tabellenbreite, die idealerweise auf die entsprechende Seitenbreite angepasst sein sollte, ebenso wie die Tabellenbeschriftung und die Zeilen- sowie die Spaltensumme.
Zunächst wird über den Befehl mutate() die Summe der Zeilen generiert und in einer neuen Spalte total_col ausgewiesen. Der vorherige Befehl wird dazu um eine weitere Zeile ergänzt.
table_sfo <- dkf %>%
group_by(D17_Schueler_Schulform_Lang, D18_Schueler_Schulform_Lang) %>%
summarize(n = n()) %>%
pivot_wider(names_from = D18_Schueler_Schulform_Lang, values_from = n) %>%
mutate(total_col = sum(across(where(is.numeric))))Die Ergänzung der Tabelle um die Summe der Spalten ist etwas komplexer. Um die Tabelle um eine Summenzeile zu ergänzen, ist in diesem Fall die folgende Ergänzung erforderlich:
table_sfo <- dkf %>%
group_by(D17_Schueler_Schulform_Lang, D18_Schueler_Schulform_Lang) %>%
summarize(n = n()) %>%
pivot_wider(names_from = D18_Schueler_Schulform_Lang, values_from = n) %>%
mutate(total_col = sum(across(where(is.numeric)))) %>%
bind_rows(mutate(., D17_Schueler_Schulform_Lang="total_row")) %>%
group_by(D17_Schueler_Schulform_Lang) %>%
summarize_all(sum) %>%
arrange(factor(D17_Schueler_Schulform_Lang, levels = c("Grundschule", "Gymnasium", "Sonderschule", "Stadtteilschule", "total_row")))In den vier zusätzlichen Zeilen werden zunächst die Summen der Spalten über die Variable D17_Schueler_Schulform_Lang gebildet und die neu generierte Zeile an den vorhandenen Datenframe über den Unterbefehl bind_rows() Datenframe angefügt. Zuletzt wird die Sortierung des Datenframes manuell über den Unterbefehl arrange() angepasst. Dies ist dann erforderlich, wenn sich die Summenzeile am Ende des Datenframes befinden soll, deren logische Position bei einer alphabetischen Sortierung der Gruppierungsvariablen jedoch nicht die letzte ist. Die erzeugte Tabelle enthält nun bereits alle Daten, die ausgewiesen werden sollen, erfüllt jedoch noch immer nicht die Kriterien einer veröffentlichungsreifen Tabelle:
flextable(table_sfo)D17_Schueler_Schulform_Lang | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | total_col |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
total_row | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Um eine weitere Spalte hinzuzufügen, die eine “saubere” Bezeichnung der einzelnen Tabellenbestandteile erlaubt, kann über den Befehl add_column() eine Spalte, welche die gewünschten Bezeichnungen enthält, hinzugefügt werden.17 Der Unterbefehl .before = T legt dabei fest, dass diese Spalte an den Anfang des Datenframes gestellt werden soll.
table_sfo <- table_sfo %>% add_column("Schulform (Schuljahr 2017/18)" = c("Grundschule", "Gymnasium", "Sonderschule", "Stadtteilschule", "insgesamt"),.before = T)
flextable(table_sfo)Schulform (Schuljahr 2017/18) | D17_Schueler_Schulform_Lang | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | total_col |
Grundschule | Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | total_row | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Anschließend können die Spaltenbezeichnungen über den Befehl colnames() vereinheitlicht werden:
colnames(table_sfo) <- c("Schulform (Schuljahr 2017/18)", "D17_Schueler_Schulform_Lang", "Grundschule", "Gymnasium", "Sonderschule", "Stadtteilschule", "insgesamt")
flextable(table_sfo)Schulform (Schuljahr 2017/18) | D17_Schueler_Schulform_Lang | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | total_row | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Nun sollen die zweite Spalte, die inhaltsgleich mit der ersten Spalte ist, entfernt werden und die übrigen Spalten, mit Ausnahme der ersten Spalte, eine gemeinsame Überschrift bekommen, sodass ersichtlich ist, aus welchem Schuljahr die Angaben stammen. Um ersteres zu erreichen kann der Befehlt col_keys = c() aus dem flextable-Paket eingesetzt werden. Für zweiteres kann der Befehl add_header_row verwendet werden. Zu definieren sind hier die angestrebten Bezeichnungen im Unterbefehl values = c() sowie die Spalten, auf die sich diese Bezeichnungen beziehen – im Unterbefehl colwidths = c().
flextable_sfo <- flextable(table_sfo, col_keys = c("Schulform (Schuljahr 2017/18)", "Grundschule", "Gymnasium", "Sonderschule", "Stadtteilschule", "insgesamt"))
flextable_sfo <- add_header_row(flextable_sfo, values = c("", "Schulform (Schuljahr 2018/19)"), colwidths = c(1, 5))
flextable_sfoSchulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Schließlich können noch benutzerdefinierte Formatierungen an der Tabelle vorgenommen werden. Beispielsweise sollen hier die letzte Zeile und die letzte Spalte (also die Zeile und Spalte insgesamt) kursiv dargestellt werden. Dies ist über folgenden Code möglich:
flextable_sfo <- italic(flextable_sfo,i =flextable_sfo[["body"]][["content"]][["content"]][["nrow"]], part="body")
flextable_sfo <- italic(flextable_sfo,j =flextable_sfo[["body"]][["content"]][["content"]][["ncol"]], part="all")
flextable_sfoSchulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
In ähnlicher Weise lassen sich auch einzelne Zeilen oder Zellen farbig hervorheben. So können über den Befehl bg() bedingte Formatierungen definiert werden. Beispielhaft werden hier die Werte in der Spalte Gymnasium hervorgehoben, die in der Spalte Grundschule Werte im Zahlenbereich 1260–2000 aufweisen. Derartige Formatvorgaben sind miteinander kombinierbar und ebenso auf ganze Zeilen und Spalten anwendbar.
flextable_sfo <- bg(flextable_sfo, i = ~ Grundschule > 1260 & Grundschule < 2000, j = ~ Gymnasium,
bg = alpha("#003063",0.2))
flextable_sfoSchulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Zuletzt kann die Tabelle noch auf die benötigte Seitenbreite angepasst werden. Dies ist in HTML Dokumenten in der Regel nicht erforderlich, da in selbigen eine automatische Skalierung der Tabelle erfolgt. Bei der Erstellung von WORD-Dokumenten, wie in diesem Beispiel, ist dieser Schritt jedoch ratsam. Zur Skalierung der Tabelle auf die exakte Seitenbreite bietet sich die folgende Hilfsfunktion FitFlextableToPage (Sarah 25.07.2019) an, die sich als tragfähig für diese Aufgabe erwiesen hat. So kann zunächst über den Unterbefehlt pgwidth definiert werden, auf welche Breite die Tabelle angepasst werden soll – in diesem Fall 16.59 cm, die von WORD vorgebene optimale Tabellenbreite, geteilt durch 2,54 um den entsprechenden Wert in Inch zu erhalten. Anschließend kann die Funktion über den Befehl FitFlextableToPage() genutzt werden und die Tabelle mit der gewünschten Breite ausgegeben werden.
FitFlextableToPage <- function(ft, pgwidth = 16.59/2.54){
ft_out <- ft %>% autofit()
ft_out <- width(ft_out, width = dim(ft_out)$widths*pgwidth /(flextable_dim(ft_out)$widths))
return(ft_out)
}
FitFlextableToPage(flextable_sfo)Schulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Sollten die Spaltenbreiten, wie in diesem Beispiel noch nicht ideal verteilt sein, ist etwas manuelle Nacharbeit möglich. Mit folgendem Code können die Breiten der einzelnen Spalten entsprechend angepasst werden. Die Spalten können dabei entweder über ihren Namen oder über ihre Position angesteuert werden. Mit diesen Formatierungen sollte jedoch mit bedacht umgegangen werden, da das Auffinden der korrekten Spaltenbreite in der Regel mit einer Reihe von Versuchen nach dem Trial and Error Prinzip verbunden ist.
flextable_sfo <- width(flextable_sfo, j = ~ `Schulform (Schuljahr 2017/18)`, width = (2.88/2.54))
flextable_sfo <- width(flextable_sfo, j = ~ Grundschule, width = (2.88/2.54))
flextable_sfo <- width(flextable_sfo, j = 3, width = (2.88/2.54))
flextable_sfo <- width(flextable_sfo, j = 4, width = (2.88/2.54))
flextable_sfo <- width(flextable_sfo, j = 5, width = (2.88/2.54))
flextable_sfo <- width(flextable_sfo, j = 6, width = (2.21/2.54))
flextable_sfoSchulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
Darauf aufbauend, kann nun das Erscheinungsbild der Tabelle finalisiert werden. Dazu können beispielsweise sogenannte themes genutzt werden, die vordefinierte Designvorlagen darstellen. Sollten diese nicht den eigenen Vorstellungen entsprechen, ist ebenso der Einsatz von benutzerdefinierten Designvorlagen möglich. Um ein solches Theme zu nutzen, ist eine Codezeile ausreichend:
flextable_sfo %>% theme_booktabs()Schulform (Schuljahr 2018/19) | |||||
Schulform (Schuljahr 2017/18) | Grundschule | Gymnasium | Sonderschule | Stadtteilschule | insgesamt |
Grundschule | 1,257 | 1,306 | 1,198 | 1,249 | 5,010 |
Gymnasium | 1,297 | 1,348 | 1,306 | 1,257 | 5,208 |
Sonderschule | 1,216 | 1,219 | 1,062 | 1,176 | 4,673 |
Stadtteilschule | 1,298 | 1,311 | 1,136 | 1,364 | 5,109 |
insgesamt | 5,068 | 5,184 | 4,702 | 5,046 | 20,000 |
6.2 Erstellung eines Balkendiagramms
Ein einfaches Balkendiagramm kann in R mit dem Befehl barplot() erzeugt werden. So generiert der nachfolgende Befehl beispielsweise ein Balkendiagramm, welches die Häufigkeit der Lernförderungen in den Schuljahren 2017/18 und 2018/19 nebeneinander darstellt.
barplot(table(dkf$D17_LF_1, dkf$D18_LF_1), beside = T)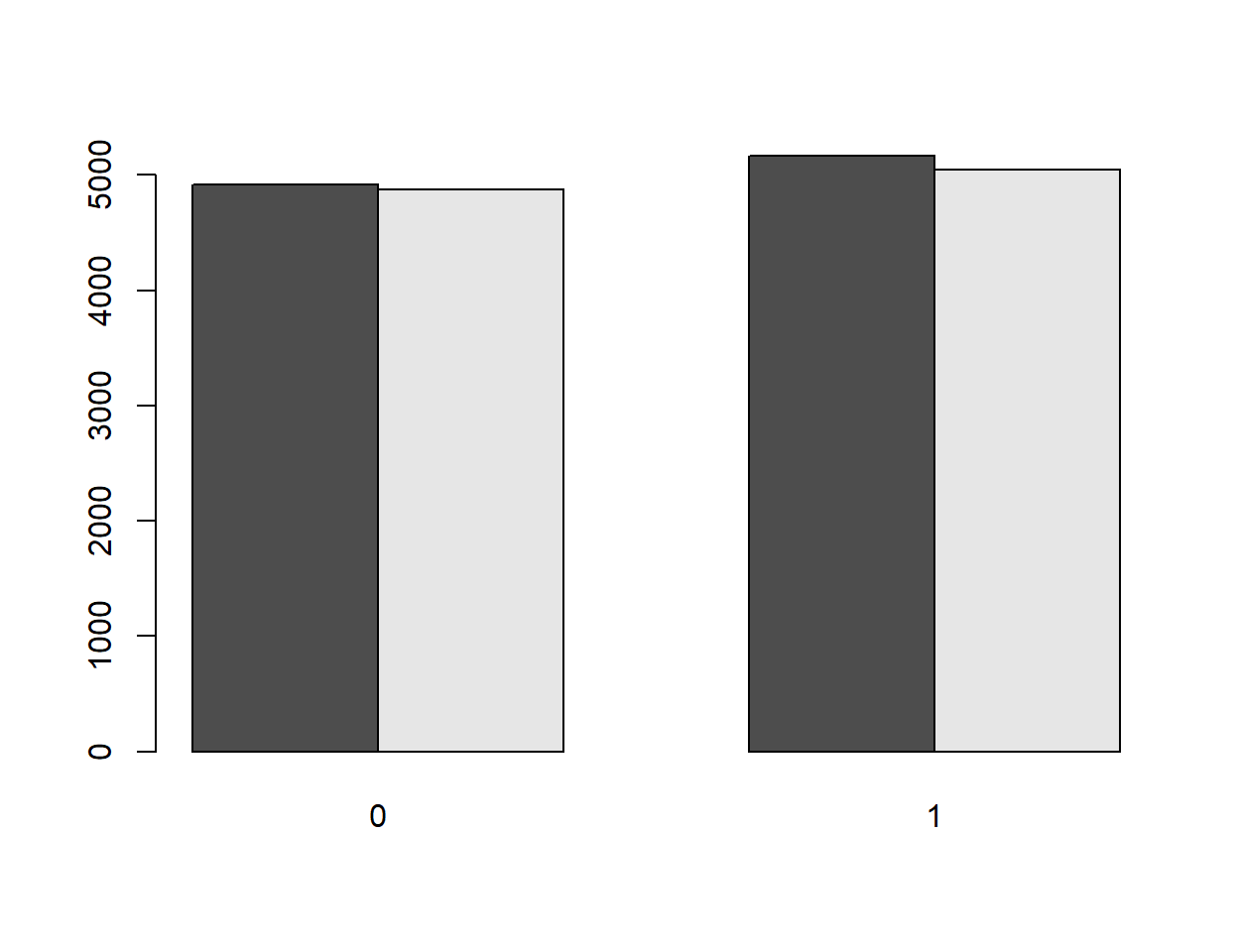
Genau wie bei der Erstellung einer Tabelle kann hierbei die Ausgabe variiert werden und beispielsweise statt der absoluten Zahlen die Anteile ausgegeben werden:
barplot(proportions(table(dkf$D17_LF_1, dkf$D18_LF_1)), beside = T)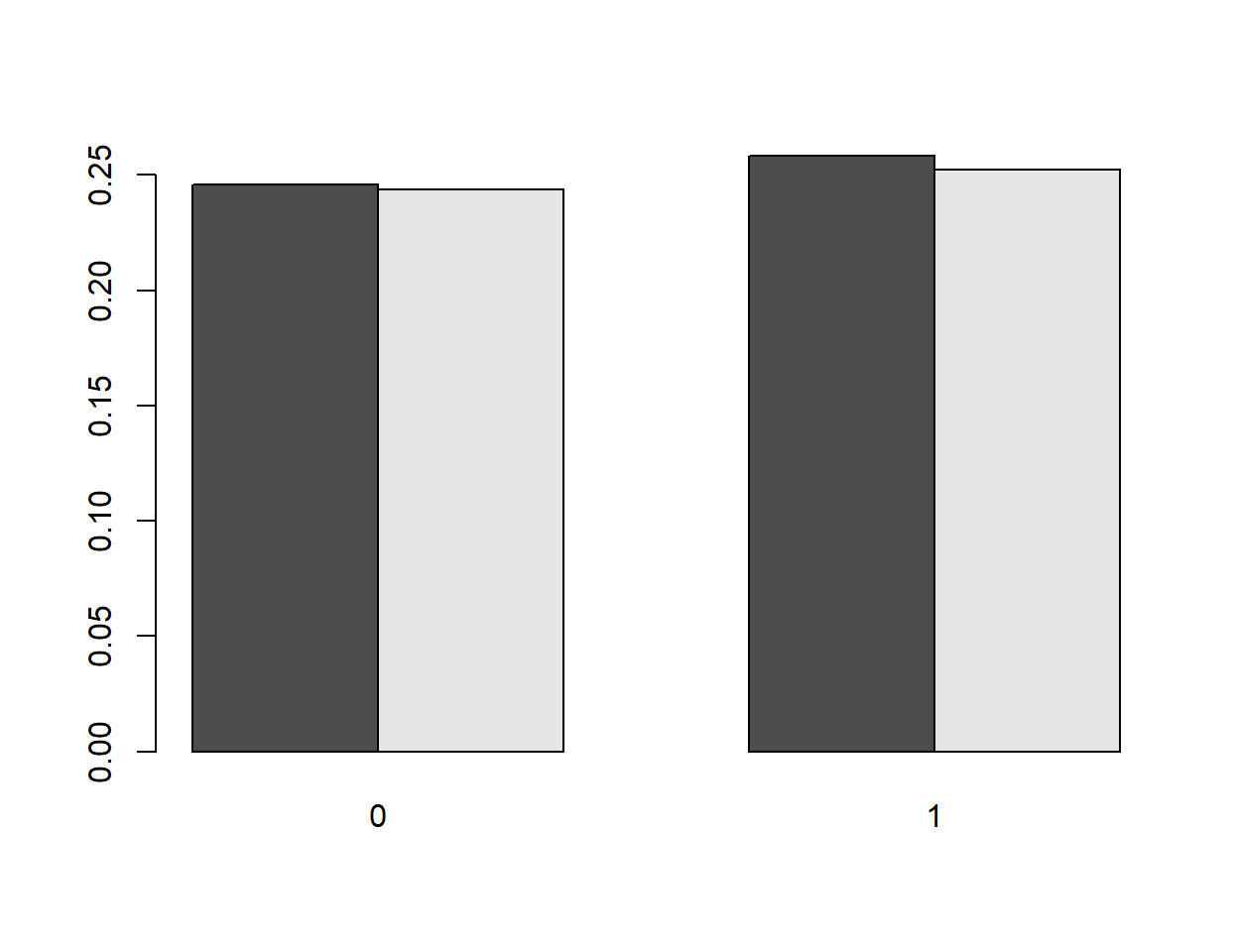
Auch sind Anpassungen an der farblichen Darstellung, der Breite der Balken und weiteren Aspekten der Abbildung möglich – dennoch bietet es sich an, für die Erstellung von Abbildungen auf das umfangreiche Paket ggplot2 (Wickham, Chang, et al. 2021) zurückzugreifen, welches vielfältige Darstellungen für nahezu jeden Kontext ermöglicht. Die Grundidee des Pakets geht dabei auf die Grammar of Graphics (Wilkinson 2005) und die Vorstellung, zurück dass Abbildungen in der Statistik sich grundsätzlich aus (transformierten) Daten, einem Koordinatensystem und den dargestellten Elementen (inklusive ihrer ästhetischen Eigentschaften) zusammensetzen (Wilkinson 2005, 7).
Zur Darstellung von Daten mit ggplot ist es ratsam, zunächst die Daten in die entsprechende Form zu bringen. Dies ist nicht zwingend erforderlich und kann prinzipiell auch im Aufruf für die Erstellung einer Abbildung geschehen, erleichtert jedoch die Arbeit an der Abbildung. Angenommen, es sollen die Förderanteile der Schülerinnen und Schüler über verschiedene Schuljahre hinweg dargestellt werden, so sind diese Anteile zunächst zu berechnen. Dazu wird – wie bereits oben für die Erstellung von Tabellen – das Paket dplyr genutzt. Der folgende Befehl generiert einen Datensatz im long-Format, der aus zwei Spalten mit jeweils drei Werten besteht (adaptiert nach Schlegel and mpalanco 23.09.2015).
data_plot_lf <- dkf %>%
group_by() %>%
summarize(across(contains("LF_1"), ~ sum(.[. == 1])/n())) %>%
pivot_longer(., cols = contains("LF_1"))Auf Basis dieses kleinen Datenframes kann nun ein Balkendiagramm mit ggplot() erzeugt werden. Dazu sind in der Mindestvariante der Datenframe zu benennen, auf dem die Abbildung basieren soll, sowie im Unterbefehl aes() Vorgaben für das grundsätzliche Erscheinungsbild, in diesem Fall die Merkmale x= und y= zu machen. Der Unterbefehl geom_bar(stat = “identity”) gibt schließlich an, dass ein Balkendiagramm erstellt werden soll. Bereits an diesem kurzen Code wird deutlich, dass die einzelnen Bestandteile einer Abbildung über das + Zeichen aneinandergereiht werden können. Diese Aneinanderreihung kann beliebig fortgesetzt werden, um weitere Anpassungen an der Abbildung vorzunehmen.
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity")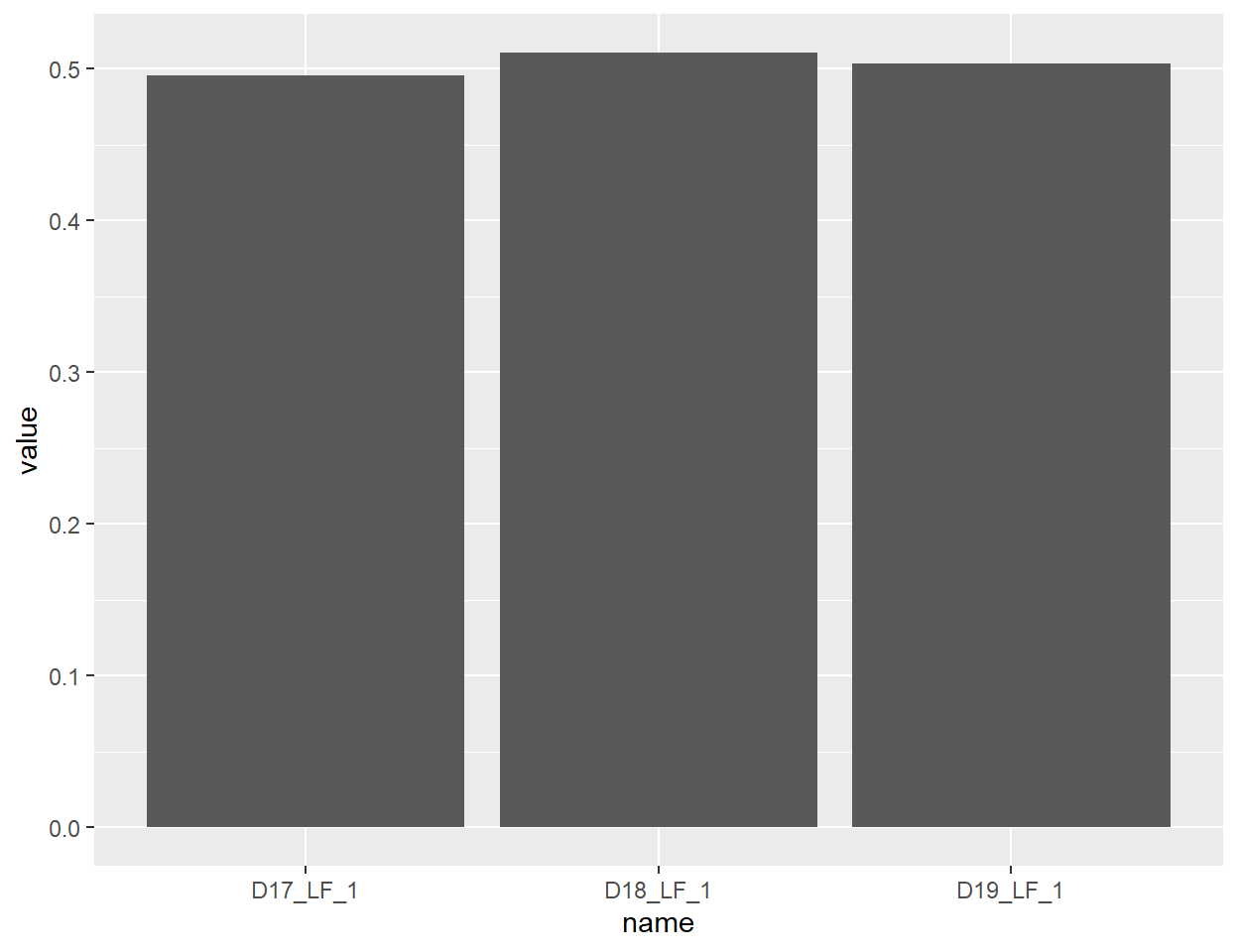
Die Möglichkeit der Aneinanderreihung weiterer Vorgaben für die dargestellten Elemente der Abbildungen, lässt sich nutzen, um die Abbildung nach den eigenen Vorgaben zu gestalten. So lässt sich mit dem Unterbefehl coord_flip() das Diagramm um 90° kippen, sodass aus den vertikalen Balken horizontale Balken werden.
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity") +
coord_flip()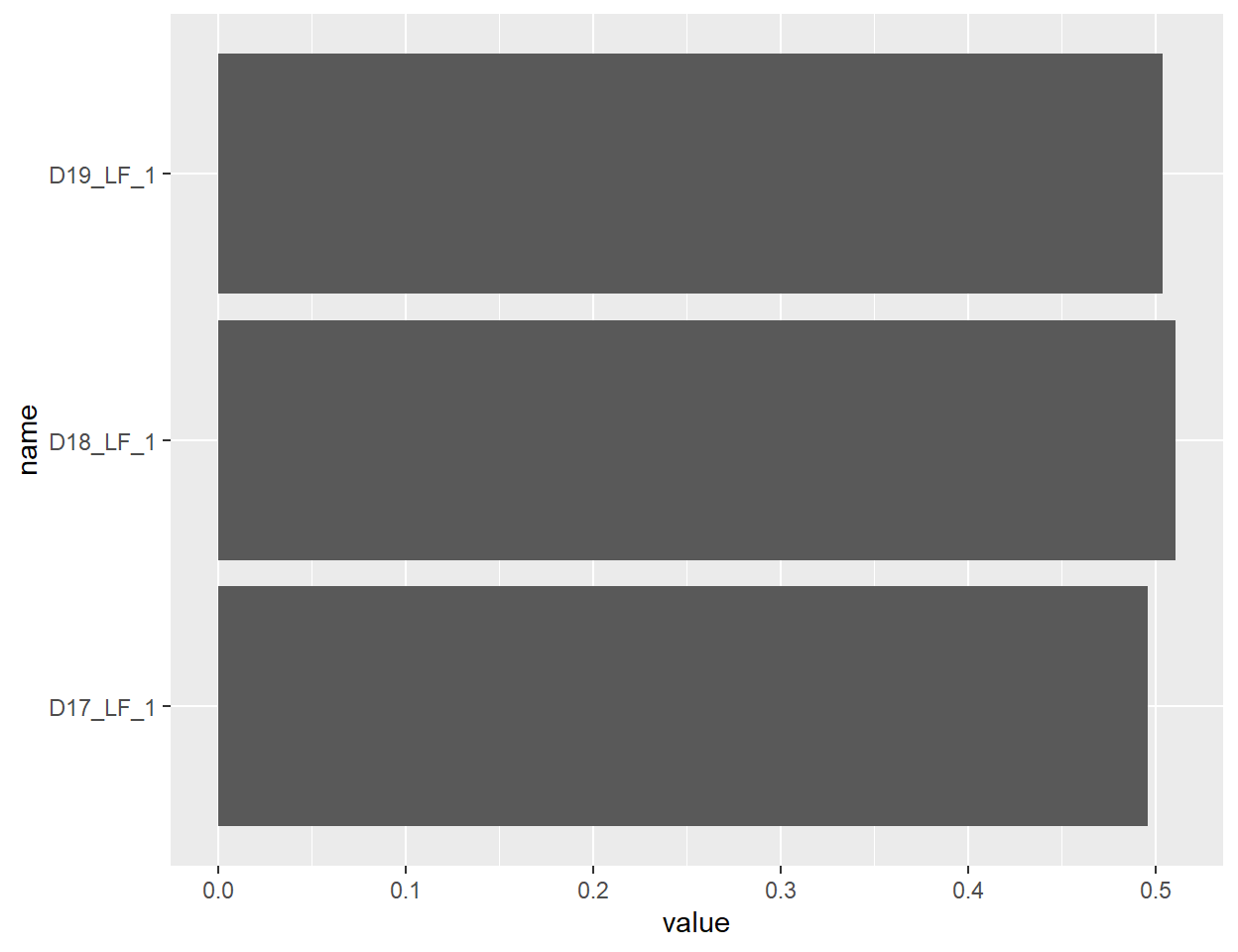
Anschließend lassen sich über den Unterbefehl fill = die Farben der Balken anpassen. In diesem Fall wird jeder der Balken in einer über einen html-Code definierten Farbe eingefärbt. Grundsätzlich kann damit ein breiter Farbbereich abgedeckt werden. Andere Möglichkeiten zur Definition der Farben bestehen beispielsweise in der Angabe von in R verfügbaren Farbskalen oder der Nutzung von expliziten Farbbenennungen (beispielsweise “red”).
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity",
fill = c("#B5D8FA", "#2E7FD2", "#003063")) +
coord_flip()
Über die Unterbefehle scale_y_continuous() sowie scale_x_discrete() lassen sich unter anderem die Achsenbeschriftung und die Skalierung der Achsen anpassen. Die zu modifizierende Achse wird dabei über die Angabe x oder y definiert. In diesem Fall ist zu beachten, dass über den vorherigen Unterbefehl coord_flip() bereits eine Drehung der Achsen stattgefunden hat, sodass in diesem Fall die y-Achse die horizontale Achse bezeichnet. Stets mitzubedenken sind daher die Implikationen eines Befehls auf die gesamte Abbildung. Der Befehlt percent_format() aus dem Paket scales (Wickham and Seidel 2020) ermöglicht dabei auf einfache Weise die Anpassung der Achsenbeschriftung auf ein Prozentformat. Angegeben werden kann im Unterbefehl accuracy = auch die gewünschte Genauigkeit der gerundeten Werte – hier ganze Zahlen. Ebenso wird mit dem Befehl limits = c() die Begrenzung der y-Achse festgelegt – in diesem Fall auf einen Wertebereich zwischen 0 % und 100 %. Die Beschriftung der diskreten Variable erfolgt hingegen über die explizite Angabe der Schuljahre in einem Zeichenfolgenobjekt.
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity",
fill = c("#B5D8FA", "#2E7FD2", "#003063")) +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
scale_x_discrete(labels = c("Schuljahr 2017/18", "Schuljahr 2018/19", "Schuljahr 2019/20"))
In ähnlicher Art und Weise können Wertebeschriftungen zu den einzelnen Balken hinzugefügt werden. Hierzu ist der Befehl geom_text() zu nutzen, welcher mit verschiedenen Unterbefehlen die Art der dargestellten Beschriftungen (Unterbefehl aes(label=)), deren vertikale und horizontale Ausrichtung (Unterbefehle vjust= und hjust=) sowie die Größe der Beschriftung (Unterbefehl size=) und ihre Farbe (Unterbefehl colour =) definiert.
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity",
fill = c("#B5D8FA", "#2E7FD2", "#003063")) +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
scale_x_discrete(labels = c("Schuljahr 2017/18", "Schuljahr 2018/19", "Schuljahr 2019/20")) +
geom_text(aes(label=percent(value, accuracy = .1)), vjust=0.25, hjust = -.2, size=3, colour = "black")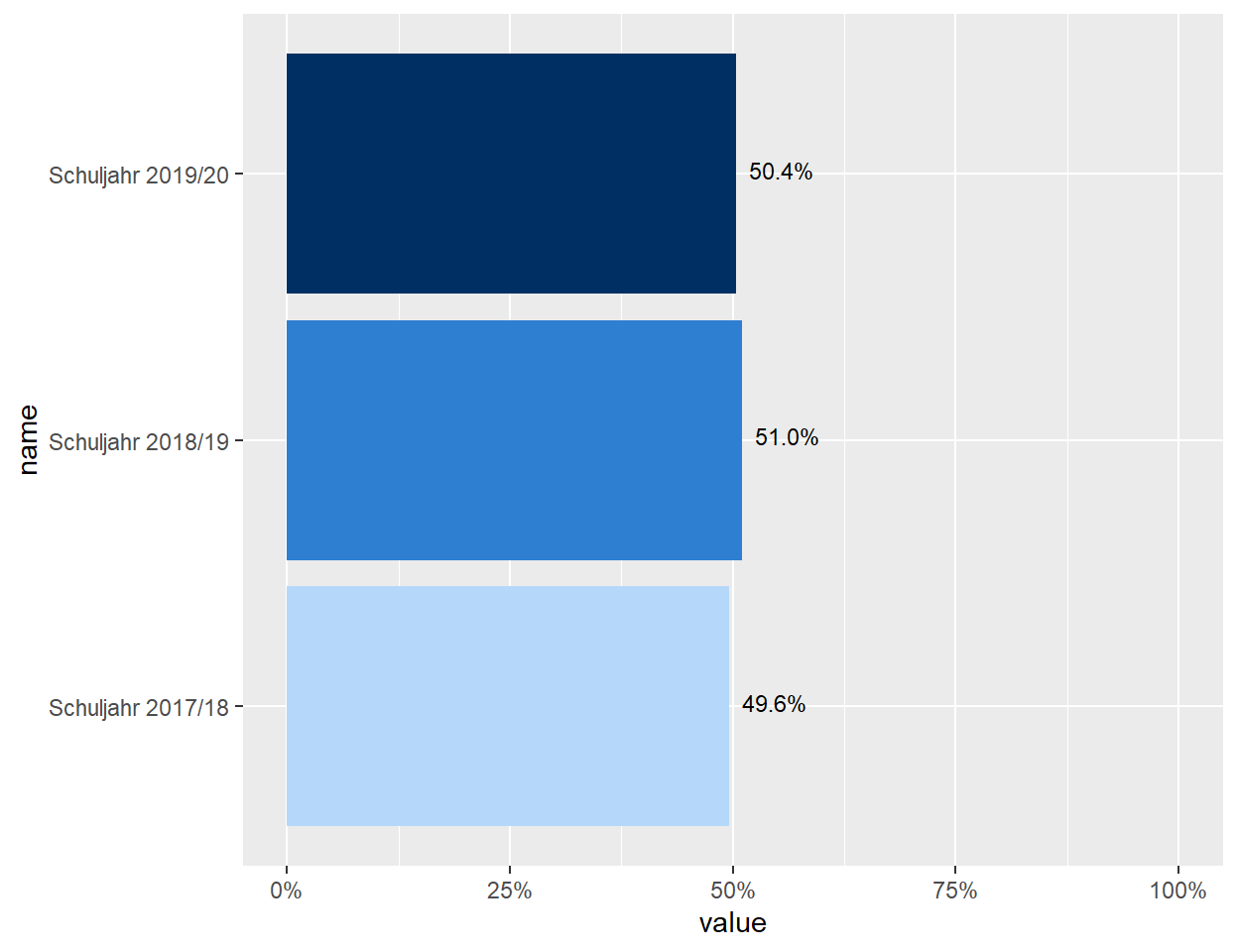
Schließlich können über die Nutzung eines Themes, in diesem Fall theme_minimal(), oder die explizite Angabe von Darstellungselementen über den Befehl theme(), Anpassungen an der Darstellung vorgenommen werden.18 So werden in diesem Fall über die Befehle axis.title.x=element_blank() sowie axis.title.y=element_blank() die Achsenbeschriftungen beider Achsen entfernt. Diese Vorgaben für die Darstellung von Abbildungselementen können auch in ein benutzerdefiniertes Theme übernommen werden, welches für weitere Abbildungen genutzt werden kann. Die Nutzung solcher benutzerdefinierten Themes stellt eine Vereinfachung für die Generierung von Abbildung dar, solange immer mit denselben Vorgaben für die Gestaltung von Abbildungen gearbeitet wird.
ggplot(data_plot_lf, aes(x=name, y=value)) +
geom_bar(stat = "identity",
fill = c("#B5D8FA", "#2E7FD2", "#003063")) +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
scale_x_discrete(labels = c("Schuljahr 2017/18", "Schuljahr 2018/19", "Schuljahr 2019/20")) +
geom_text(aes(label=percent(value, accuracy = .1)), vjust=0.25, hjust = -.2, size=3, colour = "black") +
theme_minimal() +
theme(axis.title.x=element_blank(), axis.title.y=element_blank())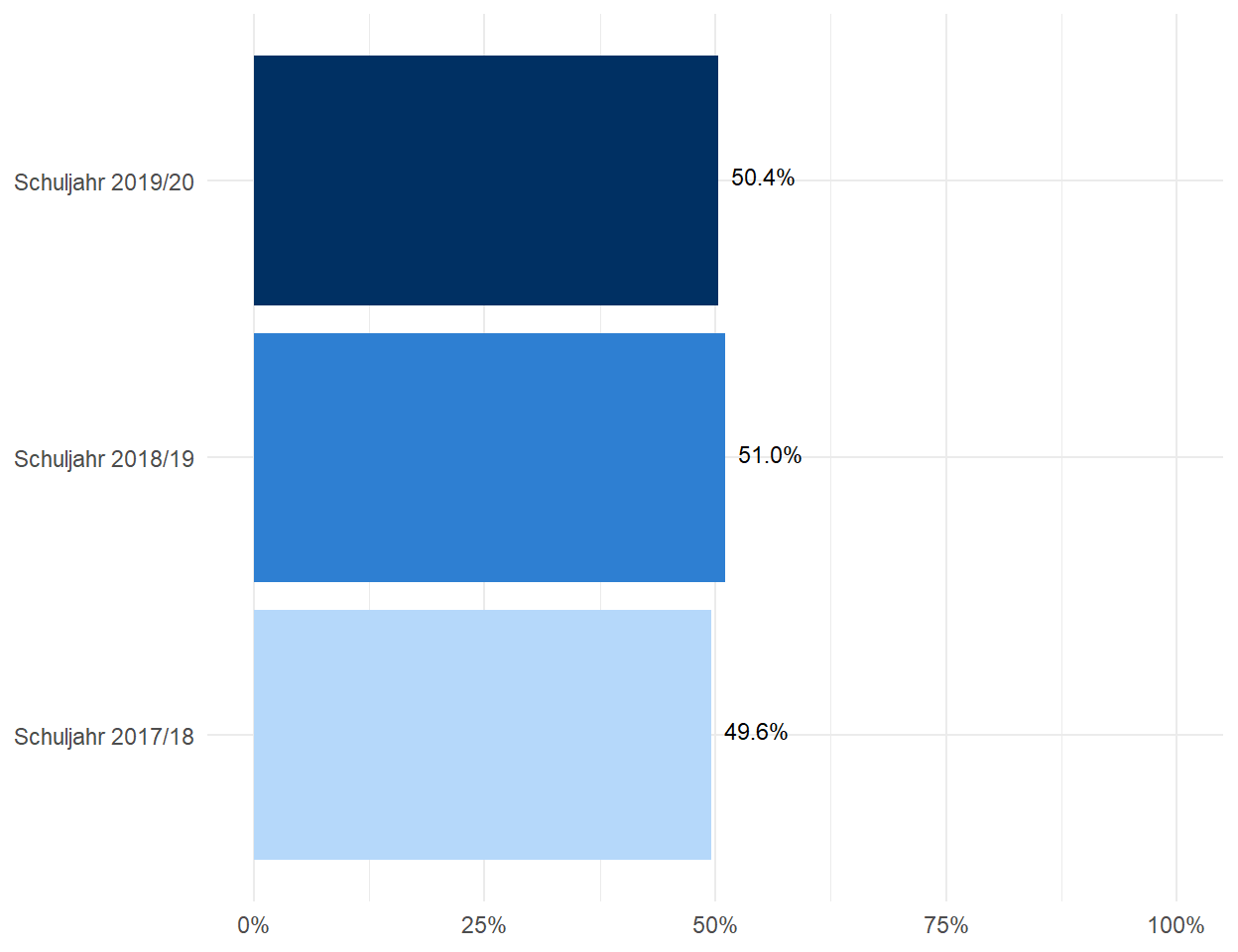
Zur Ergänzung einer Legende in diesem Diagramm sind weitere Anpassungen erforderlich. So muss zunächst in der ersten Codezeile im Unterbefehl aes() ergänzt werden, welche Variable zur Bestimmung der Balkenfarbe genutzt werden soll – in diesem Fall fill=name – also die Variable, welche die Bezeichnungen der Förderungen der einzelnen Schuljahre enthält. Zudem wird der Befehl scale_x_discrete() durch den Befehl scale_fill_manual() ersetzt, welcher auch die html-Werte der zu nutzenden Farben aus dem Befehl geom_bar() übernimmt. Im Befehl labs() werden der Titel der Legende (Unterbefehl fill =) sowie die Anmerkung (Unterbefehl caption=) definiert. Abschließend wird im Befehl guides() noch die Reihenfolge der Legende umgekehrt, sodass die Reihenfolge der Farben in der Legende der Reihenfolge der Balken in der Darstellung entspricht.
ggplot(data_plot_lf, aes(x=name, y=value, fill=name)) +
geom_bar(stat = "identity") +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
scale_fill_manual(labels = c("2017/18","2018/19","2019/20"), values = c("#B5D8FA", "#2E7FD2", "#003063")) +
geom_text(aes(label=percent(value, accuracy = .1)), vjust=0.25, hjust = -.2, size=4, colour = "black") +
theme_minimal() +
theme(axis.title.x=element_blank(), axis.title.y=element_blank(),
legend.position = "right", legend.title = element_text(size = 13),
axis.text.y = element_blank(),
plot.caption = element_text(hjust = 0),
legend.text = element_text(size = 13)) +
labs(fill = "Schuljahr", caption = "Anmerkung: Sprachförderbedarf Jg. 1-10, ohne IVK und Basisklassen; Lernförderbedarf Jg. 1-13, nur Regelklassen; Quelle: DiViS") +
guides(fill = guide_legend(reverse = T)) 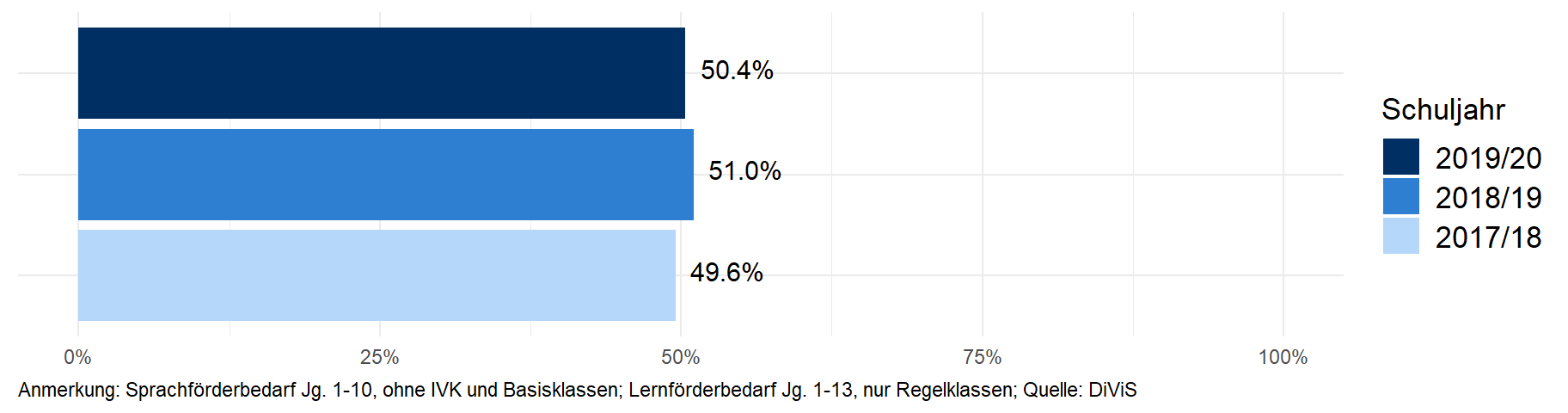
Um schließlich eine Abbildung zu erzeugen, die möglichst exakt dem Original entspricht, wird schließlich noch die Überschrift der Legende getilgt, eine Umrandung für die Abbildung erzeugt sowie eine Abbildungsüberschrift hinzugefügt. Eine einfache Möglichkeit zur Tilgung der Überschrift der Legende ist im Befehl theme() den Unterbefehl legend.title = element_blank() zu setzen. Dies ignoriert jede Festlegung des Legendentitels an anderer Stelle. Ebenso könnte im Befehl labs() auf die Defintion des Unterbefehls fill = verzichtet werden. Die Umrandung um die Abbildung wird an derselben Stelle über den Unterbefehl plot.background = geregelt. In diesem Fall wird ein schwarzes Rechteck ohne Füllung mit einer definierten Größe auf die Abbildung gelegt. Zudem wird über den Unterbefehl panel.grid = die Darstellung der Hilfslinien im Diagramm bestimmt – hier werden alle Linien im Diagramm entfernt. Schließlich wird der Diagrammtitel über den Befehl ggtitle() hinzugefügt.19
ggplot(data_plot_lf, aes(x=name, y=value, fill=name)) +
geom_bar(stat = "identity") +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = .1), limits = c(0,1)) +
scale_fill_manual(labels = c("Sj. 2017/18","Sj. 2018/19","Sj. 2019/20"), values = c("#B5D8FA", "#2E7FD2", "#003063")) +
theme_minimal() +
theme(axis.title.x=element_blank(), axis.title.y=element_blank(),
legend.position = "right", legend.title = element_blank(),
axis.text.y = element_blank(),
plot.caption = element_text(hjust = 0),
plot.background = element_rect(colour = "black", fill=NA, size=1),
panel.grid = element_blank()) +
labs(fill = "Schuljahr", caption = "Anmerkung: Sprachförderbedarf Jg. 1-10, ohne IVK und Basisklassen; Lernförderbedarf Jg. 1-13, nur Regelklassen; Quelle: DiViS") +
geom_text(aes(label=percent(value, accuracy = .1)), vjust=0.25, hjust = -.2, size=3, colour = "black") +
guides(fill = guide_legend(reverse = T)) +
ggtitle("Schülerinnen und Schüler mit Lernförderbedarf, Schuljahre 2017/18 bis 2019/20, 1. Hj.")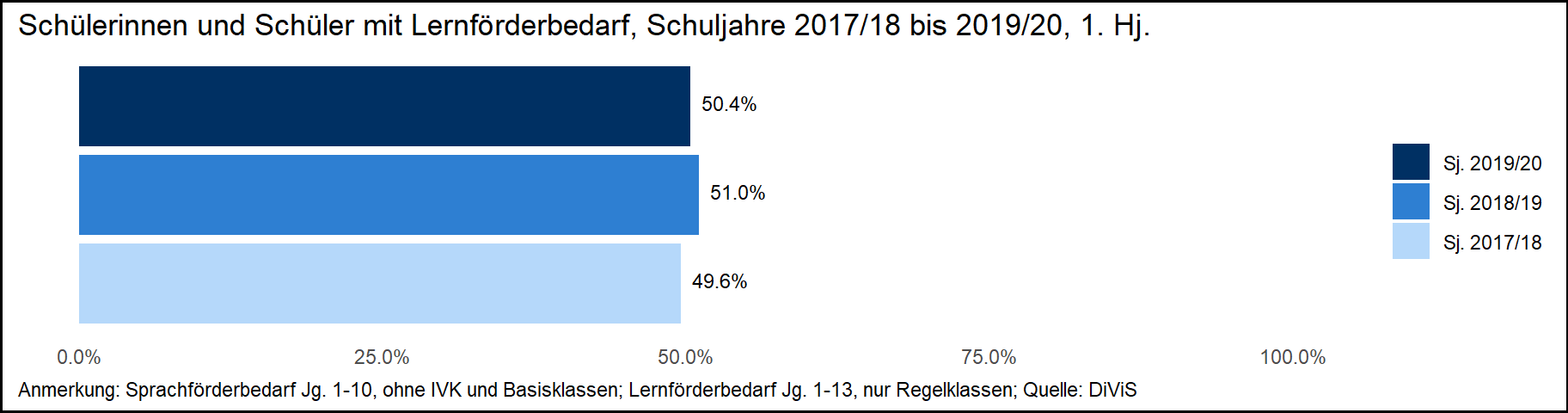
6.3 Erstellung eines gestapelten Balkendiagramms
In ähnlicher Weise wie einfache Balkendiagramme können mit R ebenso gestapelte Balkendiagramme erzeugt werden. Dazu sind lediglich kleinere Anpassungen am oben eingeführten Code vorzunehmen. Zentral ist lediglich die Ergänzung des Befehls geom_bar() um den Unterbefehl position=“stack” – wenn die übrigen Voraussetzung an die Erstellung eines gestapelten Balkendiagramms erfüllt sind.
Grundsätzlich sind also zunächst abermals die Daten in die benötigte Form zu bringen. An dieser Stelle werden beispielhaft die Angaben zu Förderungen im Bereich Deutsch und Mathematik verwendet, um die entsprechenden Anteile für die Jahrgangsstufen 1–10 darzustellen.
data_plot_lf_dm <- dkf %>%
group_by(D19_Jahrgangsstufe_akt, lf_dm) %>%
summarize(n = n()) %>%
mutate(freq = n / sum(n)) %>%
filter(D19_Jahrgangsstufe_akt <= 10, lf_dm != 0)Ähnlich wie zuvor wird zunächst über den Befehl group_by() die gewünschte Stratifizierung der Daten angegeben. Anschließend wird über summarize() die Anzahl der Fälle berechnet und darauf aufbauend über mutate() der zugehörige Anteil ausgegeben. Der Befehl filter() definiert schließlich, dass ausschließlich die Jahrgangsstufen bis zur zehnten Jahrgangsstufe sowie Angaben mit Lernförderangaben im Datenframe verbleiben sollen. Auf diese Weise wird ein Datenframe mit insgesamt 30 Zeilen erzeugt, der für jede Förderung (Deutsch = 1, Mathematik = 2 sowie Deutsch und Mathematik = 3) jeder Jahrgangsstufe die benötigten Werte beinhaltet.
Auf Basis dieses Datenframes lässt sich mit dem folgenden Befehl eine einfache Variante eines gestapelten Balkendiagramms erzeugen. Wichtig ist in diesem Fall, dass die metrischen Variablen mit dem Befehl as.factor() so definiert werden, dass sich der ordinale Charakter der Angaben in der Abbildung widerspiegelt. Anschließend wird die oben erwähnte Ergänzung im Befehl geom_bar() – position=“stack” – vorgenommen, sodass die im Datenframe enthaltenen Werte als gestapelte Balken dargestellt werden.
ggplot(data_plot_lf_dm, aes(x=as.factor(D19_Jahrgangsstufe_akt), y=freq, fill=as.factor(lf_dm))) +
geom_bar(position="stack", stat="identity")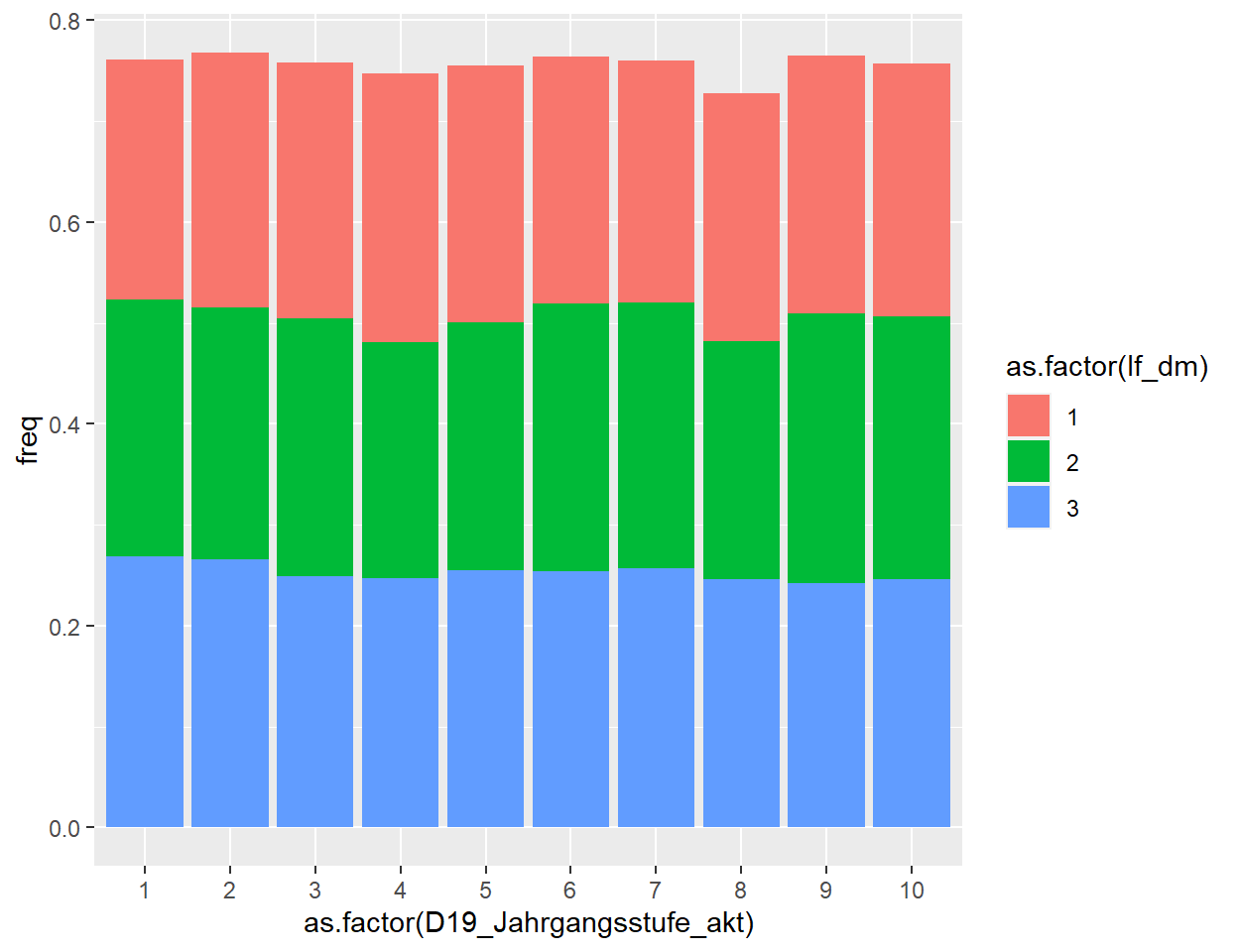
Genau wie das Balkendiagramm, kann das gestapelte Balkendiagramm über den Befehl coord_flip() um 90° gekippt werden, sodass aus den vertikalen Balken horizontale Balken werden. In gleicher Weise lässt sich über den Befehl scale_y_continuous(), die Skalierung der Achse anpassen – hier erneut auf ganzzahlige Prozentwerte. Auch die Nutzung von theme_minimal() sowie der im folgenden im Befehl theme() vorgenommenen Anpassungen, sind aus dem vorherigen Beispiel schon bekannt. In diesem Fall werden jedoch über den Unterbefehl element_text() für die Beschriftungen der x-Achse und y-Achse Textelemente definiert. Ebenso wird die Legende in diesem Fall unter dem Diagramm (legend.position = “bottom”) und nicht auf der rechten Seite dargestellt. Ebenso erfolgt das Hinzufügen einer Anmerkung erneut über den Befehl labs(). Nicht zuletzt wurde bereits im Balkendiagramm die Beschriftung der Werte innerhalb der Abbildung eingeführt (Befehl geom_text()), wobei in diesem Fall die Beschriftung in der Mitte des jeweiligen Balkenabschnitts (position = position_stack(vjust = .5)) erfolgt
ggplot(data_plot_lf_dm, aes(x=as.factor(D19_Jahrgangsstufe_akt), y=freq, fill = as.factor(lf_dm))) +
geom_bar(position="stack", stat="identity") +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1)) +
theme_minimal() +
theme(axis.title.y=element_text(), axis.text.y = element_text(),
axis.text = element_text(size=12),
legend.position = "bottom", legend.title = element_blank(),
plot.caption = element_text(hjust = 0)) +
labs(caption = "Anmerkung: Schüler*innen in Regelklassen, Jg. 1-10; Bereich Deutsch: Sprachförderung und/oder Lernförderung in Deutsch; Quelle: DiViS") +
geom_text(aes(x = D19_Jahrgangsstufe_akt, y = freq, label = percent(freq, accuracy = .1), group = lf_dm), position = position_stack(vjust = .5), size=4.5)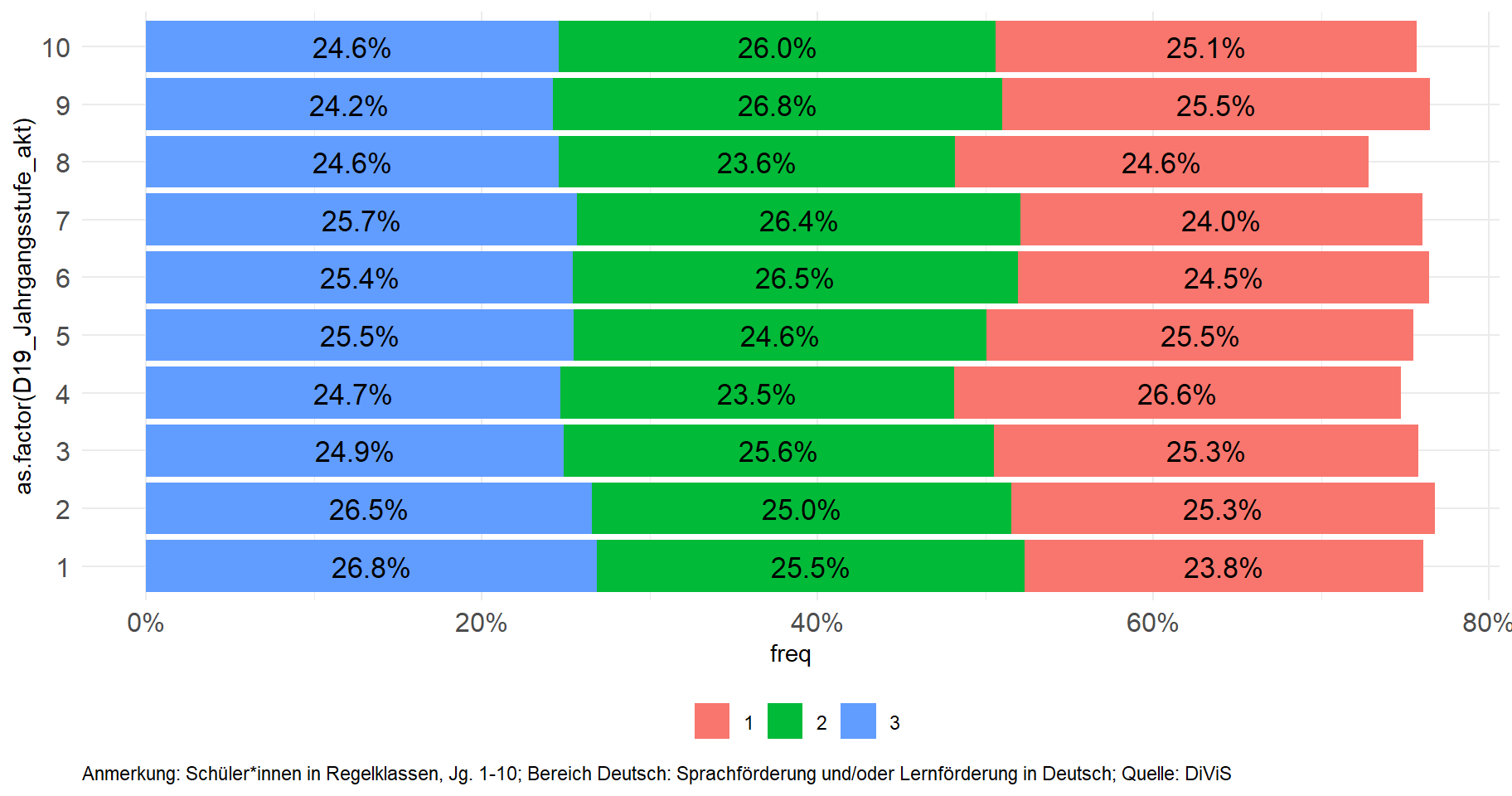
Für die Umsetzung der Abbildung entsprechend der Vorlage sind jedoch noch weitere Anpassungen erforderlich. So sind zunächst die zu verwendenden Farben zu bestimmen. Dazu werden erneut Farben verwendet, die über einen html-Code definiert werden. Zu beachten ist hier, dass die Farben in umgekehrter Reihenfolge (von rechts nach links) definiert werden (Objekt color_3_rev). Da die Farben für jeden Balken vorgehalten werden müssen, wird das ursprüngliche Objekt zudem für die Darstellung in der benötigten Anzahl – hier zehnmal – repliziert und in einem weiteren Objekt (plot_lf_dm_color_rev) abgespeichert. Dasselbe Verfahren wird für die Definition der Farben für die Wertebeschriftung angewandt (Objekt plot_lf_dm_color_text_rev). Zudem werden die Achsenbeschriftungen über die Befehle xlab() sowie ylab() definiert.
color_3_rev <- c("#B5D8FA", "#2E7FD2", "#003063")
plot_lf_dm_color_rev <- rep(color_3_rev, length(unique(data_plot_lf_dm$D19_Jahrgangsstufe_akt)))
plot_lf_dm_color_text_rev <- rep(c("black", "white", "white"), length(unique(data_plot_lf_dm$D19_Jahrgangsstufe_akt)))ggplot(data_plot_lf_dm, aes(x=as.factor(D19_Jahrgangsstufe_akt), y=freq, fill = as.factor(lf_dm))) +
geom_bar(position="stack", stat="identity") +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
theme_minimal() +
theme(axis.title.y=element_text(), axis.text.y = element_text(),
axis.text = element_text(size=12),
legend.position = "bottom", legend.title = element_blank(),
plot.caption = element_text(hjust = 0)) +
labs(caption = "Anmerkung: Schüler*innen in Regelklassen, Jg. 1-10; Bereich Deutsch: Sprachförderung und/oder Lernförderung in Deutsch; Quelle: DiViS") +
geom_text(aes(x = D19_Jahrgangsstufe_akt, y = freq, label = percent(freq, accuracy = .1), group = lf_dm), position = position_stack(vjust = .5), size=4.5, colour = plot_lf_dm_color_text_rev) +
xlab("Jahrgang") + ylab("Anteil") +
scale_fill_manual(labels = c("Förderung im Bereich Deutsch","Förderung im Bereich Deutsch und Mathe","Förderung im Bereich Mathe"), values = plot_lf_dm_color_rev) +
guides(fill = guide_legend(reverse = T)) 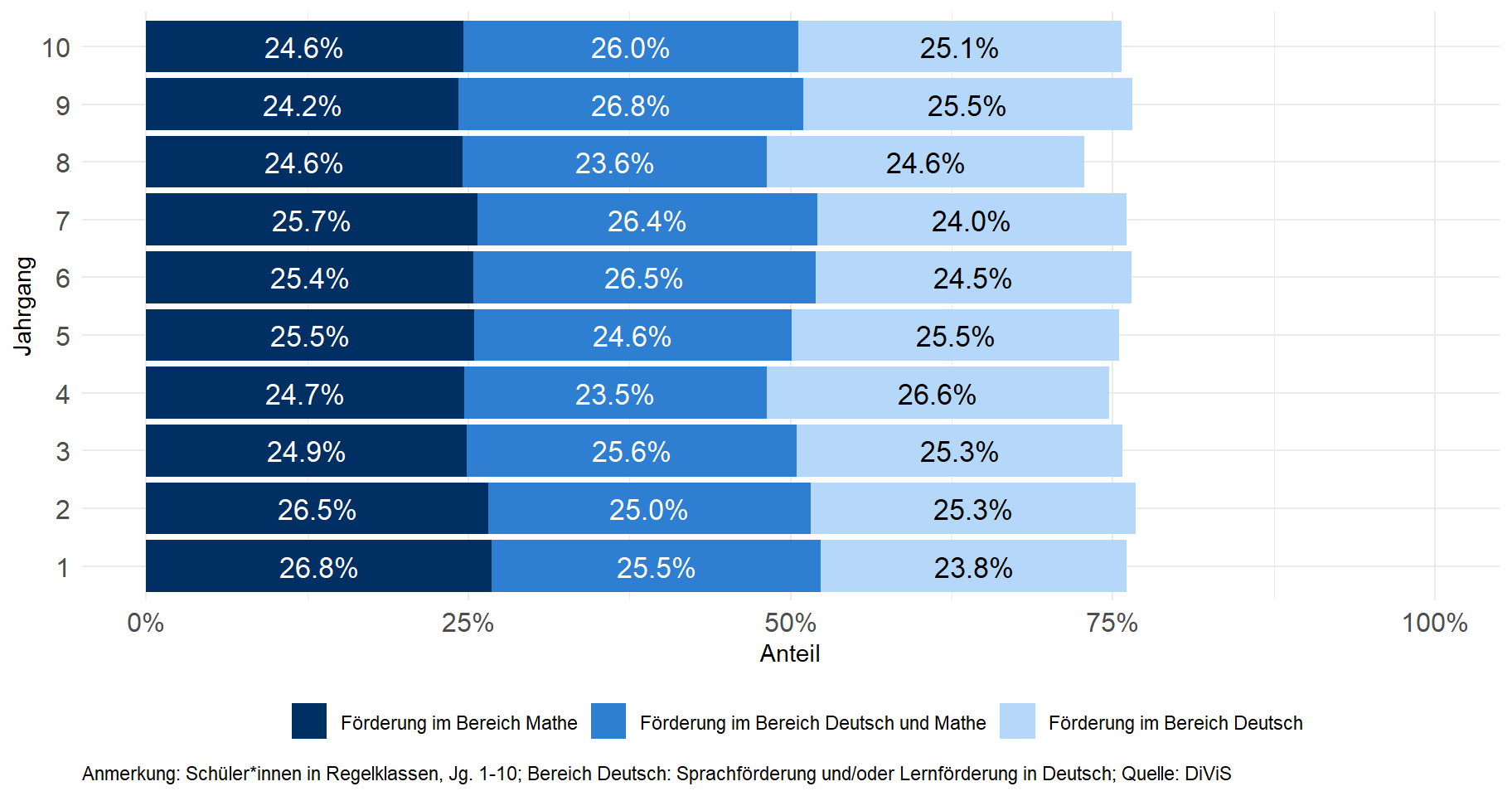
Schließlich werden noch die Überschrift (Befehl ggtitle()), der Kasten um die Abbildung hinzugefügt (Unterbefehl plot.background =) und die Hilfslinien entfernt (Unterbefehl panel.grid =). Im Titel wird hier mit dem Befehl \n ein Zeilenumbruch erzwungen.
ggplot(data_plot_lf_dm, aes(x=as.factor(D19_Jahrgangsstufe_akt), y=freq, fill = as.factor(lf_dm))) +
geom_bar(position="stack", stat="identity") +
coord_flip() +
scale_y_continuous(labels = percent_format(accuracy = 1), limits = c(0,1)) +
theme_minimal() +
theme(axis.title.y=element_text(), axis.text.y = element_text(),
axis.text = element_text(size=12),
legend.position = "bottom", legend.title = element_blank(),
plot.caption = element_text(hjust = 0),
plot.background = element_rect(colour = "black", fill=NA, size=1),
panel.grid = element_blank()) +
labs(caption = "Anmerkung: Schüler*innen in Regelklassen, Jg. 1-10; Bereich Deutsch: Sprachförderung und/oder Lernförderung in Deutsch; Quelle: DiViS") +
geom_text(aes(x = D19_Jahrgangsstufe_akt, y = freq, label = percent(freq, accuracy = .1), group = lf_dm), position = position_stack(vjust = .5), size=4.5, colour = plot_lf_dm_color_text_rev) +
xlab("Jahrgang") + ylab("Anteil") +
scale_fill_manual(labels = c("Förderung im Bereich Deutsch","Förderung im Bereich Deutsch und Mathe","Förderung im Bereich Mathe"), values = plot_lf_dm_color_rev) +
guides(fill = guide_legend(reverse = T)) +
ggtitle("Schülerinnen und Schüler mit Förderung im Bereich Deutsch und/oder Mathematik \nim Schuljahr 2019/20, 1. Hj.")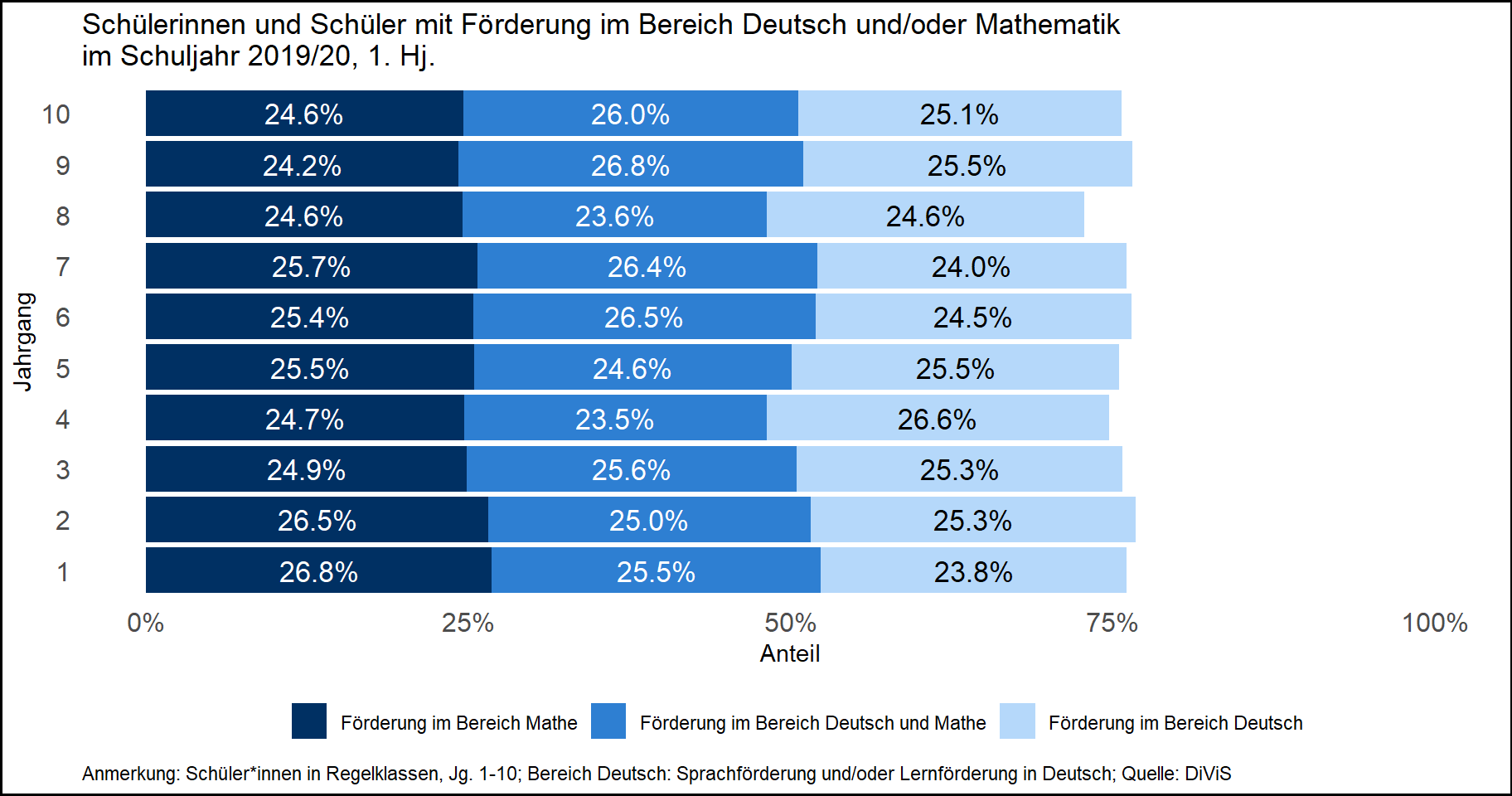
6.4 Erstellung eines schwebenden Balkendiagramms
In einer weiteren Variante des Balkendiagramms, können mit R schwebende Balkendiagramme erzeugt werden, die beispielsweise zur Visualisierung von Entwicklungen genutzt werden können. Erneut kann die obige Basis für die Erstellung der gewünschten Darstellung verwendet werden. In diesem Fall wird jedoch der Befehl geom_segment() statt des Befehl geom_bar() verwendet.
Gleichwohl ist auch bei der Erstellung eines schwebenden Balkendiagramms die Erzeugung des benötigten Datenframes der erste Schritt. In diesem Fall sollen die Leistungsentwicklungen nach Förderbedarf und Schulform visualisiert werden.
data_plot_le <- dkf %>%
group_by(D19_SFB28, D19_Schulform_akt) %>%
summarize(dl = round(mean(K719_DL, na.rm = T)),
dl_s = round(mean(K517_DL, na.rm = T)),
dl_s_1 = round(mean(K517_DL, na.rm = T)+1.5),
dl_le = round(mean(K719_DL, na.rm = T) - mean(K517_DL, na.rm = T)))Erneut wird über den Befehl group_by() die gewünschte Stratifizierung angegeben – in diesem Fall über den Förderbedarf und die Schulform. Anschließend werden über summarize() die benötigten Werte berechnet. Im Einzelnen sind dies der Endwert der Entwicklung (dl), der Startwert der Entwicklung (dl_s), der leicht erhöhte Startwert der Entwicklung (dl_s_1) sowie die Spanne der Entwicklung (dl_le).
Zu Darstellungszwecken wird dem Datenframe eine weitere Variable hinzugefügt, welche die Angaben zum Förderbedarf, die als 0 und 1 codiert sind, in “ja” und “nein” überführt. Dazu wird der Befehl ifelse() genutzt, der ermöglicht über die Abfrage des Zutreffens einer Bedingung Werte anzupassen oder neu zu vergeben.
data_plot_le$fb <- ifelse(data_plot_le$D19_SFB28 == 0, "nein", "ja") Auf Basis dieses Datenframes lässt sich mit dem folgenden Befehl eine erste Variante eines schwebenden Balkendiagramms erzeugen. Bekannt sind aus den vorherigen Abbildungen bereits die Befehle zur Generierung eines horizontalen Balkendiagramms (coord_flip()), zur Beschriftung der Achsen (xlab() sowie ylab()). Mit den weiteren Befehlen werden die Grenzen der y-Achse definiert (ylim()) und vorgegeben, dass die Daten für Schulformen separat dargestellt werden sollen (facet_wrap()). Grundlegend wird jedoch über den Befehl geom_segment() bestimmt, welche Daten für die Veranschaulichung der Entwicklung verwendet werden sollen. Zentral ist hier die Angabe der Differenzierungseinheit – hier der Förderbedarf über die Unterbefehle x= und xend= – sowie der Werte, die dargestellt werden sollen über die Unterbefehle y= und yend=.
ggplot(data_plot_le) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl)) +
coord_flip() +
xlab("Förderbedarf") +
ylab("Punkte") +
ylim(250,650) +
facet_wrap(. ~D19_Schulform_akt)
Nun entspricht diese Darstellung noch nicht der gewünschten Darstellung. Um diese zu erreichen, können im Befehl geom_segment() zudem die Größe der Balken (size=) sowie deren Farben bestimmt werden (colour=). Die Farben werden in diesem Fall vorab definiert, um den Code für die Erstellung des Diagramms zu verschlanken. Zu beachten ist, dass dazu die benötigten Farben nicht abwechselnd, sondern – in der benötigten Anzahl – nacheinander definiert werden. Zugleich wird im Befehl facet_wrap() über den Unterbefehl nrow= vorgegeben, dass die vier Teilabbildungen untereinander dargestellt werden.
data_plot_le_color <- c("#B5D8FA", "#B5D8FA", "#B5D8FA", "#B5D8FA", "#003063","#003063", "#003063", "#003063")
ggplot(data_plot_le) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl), size = 5, colour = data_plot_le_color) +
coord_flip() +
xlab("Förderbedarf") +
ylab("Punkte") +
ylim(250,650) +
facet_wrap(. ~D19_Schulform_akt, nrow = 4)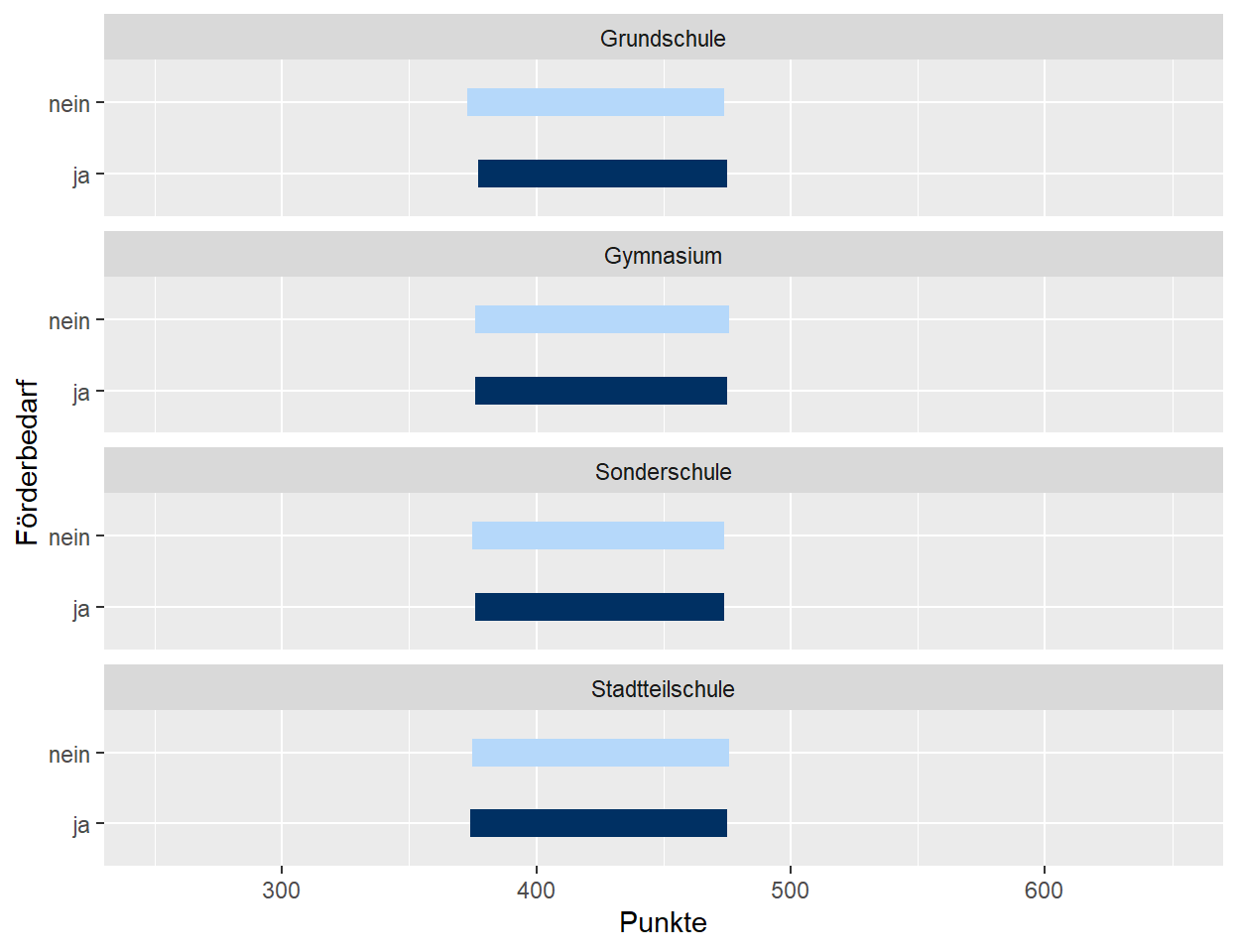
Im nächsten Schritt wird die Darstellung der Balken modifiziert und die Beschriftungen hinzugefügt. So wird zunächst über einen zweiten geom_segment() Befehl der jeweilige Ausgangswert der Balken hervorgehoben. Dies wird erreicht, indem die Variable dl_s_1 für die Angabe des Werts für yend= verwendet wird und die Größe des Balkens (size=) entsprechend modifiziert wird. Zudem werden die Texte für die Wertebeschriftungen über die beiden Befehle geom_text() hinzugefügt. Die Position der Wertebeschriftungen wird in diesem Fall über die Unterbefehle nudge_y= bestimmt. Negative Werte für diesen Unterbefehl bewirken dabei, dass die Beschriftungen links vom y-Wert dargestellt werden, während positive Werte für diesen Unterbefehl eine Beschriftung rechts des Wertes bewirken. Die passenden Werte für die Positionierung der Beschriftungen sind dabei in der Regel per trial-and-error zu bestimmen.
ggplot(data_plot_le) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl), size = 5, colour = data_plot_le_color) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl_s_1), size =7, colour = data_plot_le_color) +
geom_text(aes(x = fb, y = dl_s, label = dl_s, group = fb),size=3, nudge_y = -17) +
geom_text(aes(x = fb, y = dl, label = paste0(dl, " (+",dl_le,")"), group = fb),size=3, nudge_y = +34) +
coord_flip() +
xlab("Förderbedarf") +
ylab("Punkte") +
ylim(250,650) +
facet_wrap(. ~D19_Schulform_akt, nrow = 4)
Für die weiteren ausstehenden Modifikationen wird im folgenden ein benutzerdefiniertes Theme mit dem Namen infograph_theme() erstellt. Dies stellt einen einfachen Weg dar, um dieselben Gestaltungsvorgaben auf unterschiedliche Abbildungen anzuwenden. So werden hier Vorgaben für die Darstellung des Hintergrunds der Abbildung (plot.background), des Hintergrunds des Panels (panel.background), für die Hilfslinien (panel.grid) sowie für die Textelemente gemacht (axis.text, plot.title, axis.title, strip.text).
infograph_theme <- function() {
theme(
plot.background = element_rect(fill = "#ffffff", colour = "#ffffff"),
panel.background = element_rect(fill = "#e3e3e3"),
axis.text = element_text(colour = "#003063", family = "Arial"),
plot.title = element_text(colour = "#e10019", face = "bold", size = 18, vjust = 1, family = "Arial", (hjust = 0.5)),
axis.title = element_text(colour = "#003063", face = "bold", size = 13, family = "Arial"),
panel.grid.major.x = element_line(colour = "#003063"),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_blank(),
panel.grid.minor.y = element_blank(),
strip.text = element_text(family = "Arial", colour = "white")
)
}Unter Nutzung dieses Themes entsteht die finale Version dieser Abbildung.
ggplot(data_plot_le) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl), size = 5, colour = data_plot_le_color) +
geom_segment(aes(x = fb, xend = fb, y = dl_s, yend = dl_s_1), size =7, colour = data_plot_le_color) +
geom_text(aes(x = fb, y = dl_s, label = dl_s, group = fb),
size=3, nudge_y = -17) +
geom_text(aes(x = fb, y = dl, label = paste0(dl, " (+",dl_le,")"), group = fb),
size=3, nudge_y = +34) +
coord_flip() +
xlab("Förderbedarf") +
ylab("Punkte") +
ylim(250,650) +
facet_wrap(. ~D19_Schulform_akt, nrow = 4) +
infograph_theme()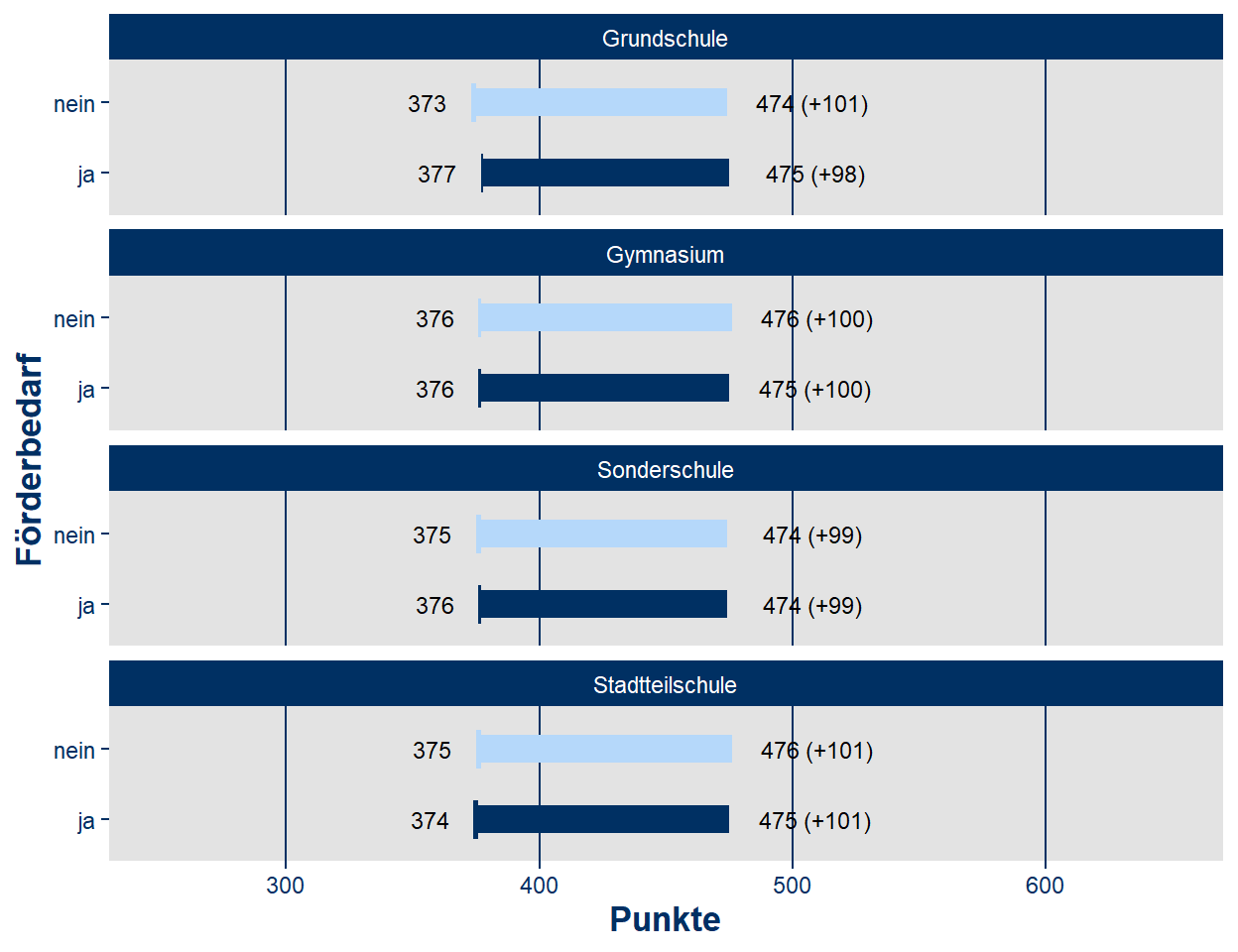
6.5 Erstellung eines Kreisdiagramms
Auch wenn der Einsatz von Kreisdiagrammen in der Statistik umstritten ist (Kosara and Skau 2016, 91–92; Cleveland and McGill 1984) da sie unter anderem nicht einfach zu lesen sind und damit zu Fehlinterpretationen führen können, sind sie nach wie vor weit verbreitet. Vor diesem Hintergrund wird die Erzeugung von Kreisdiagrammen an dieser Stelle mit einem kurzen Hinweis auf die grundsätzliche Überlegenheit von Balkendiagrammen geschildert.
Zur Erstellung des Kreisdiagramms sind zunächst erneut die Daten in die erforderliche Struktur zu bringen. Beispielhaft werden an dieser Stelle die Daten über das Personal, welches die Lernförderkurse durchführt, verwendet. Diese Daten werden mit dem nachfolgenden Befehl geladen:
kurse <- read.spss(file="C:/Reporting mit R/data/2021-06-03 kurse schuljahr 2020-21.sav", use.value.labels=FALSE, to.data.frame=TRUE)Anschließend werden die Daten über den nachfolgenden Befehl mit Hilfe des Pakets dplyr in die gewünschte Form gebracht. Wie zuvor, werden hier die bereits zuvor eingeführten Befehle group_by() und summarize() sowie mutate() genutzt.
data_plot_kurse <- kurse %>%
group_by(FSW312 = as.factor(FSW312)) %>%
summarize(n = n()) %>%
mutate(freq = n / sum(n))Dies erzeugt einen Datenframe, der neben den Ausprägungen der Variablen FSW312, welche über die Personengruppe, die den Lernförderkurs durchgeführt hat, Auskunft gibt, auch die Anzahl der Kurse (Variable n), die von der jeweiligen Personengruppe durchgeführt wurden, sowie den Anteil dieser Kurse an allen Kursen (Variable freq) enthält.
Die Beispieldaten enthalten keine Wertelabels, sodass diese zu Darstellungszwecken hinzugefügt werden sollten. Hierzu wird eine weitere Variable an den Datenframe angefügt:
data_plot_kurse$FSW312_labels <- c("eigene Lehrkräfte", "eigene sozialpäd. Fachkräfte", "pensionierte Lehrkräfte", "Studierende", "Schülerinnen und Schüler", "gewerbliche Anbieter", "Lehrkräfte im Vorbereitungsdienst", "sonst. Hochschulabsolventinnen und -absolventen", "andere")Zur Erstellung der Abbildung auf Basis des erzeugten Datenframes wird erneut das Paket ggplot2 genutzt.
ggplot(data_plot_kurse, aes(x="", y=freq, fill=FSW312)) +
geom_bar(stat="identity", width=1, color="white") +
coord_polar("y", start=0) +
theme_void()
Über den Unterbefehl aes() wird abermals definiert, welche Informationen dargestellt werden – in diesem Fall keine Information auf der x-Achse und auf der y-Achse die Variable freq, also der Anteil der Personengruppe, welche die Lernförderkurse durchgeführt hat. Ebenso wird an dieser Stelle definiert, dass die Gruppierungsvariable die Ursprungsvariable FSW312 ist. Der Befehl geom_bar() definiert in der nächsten Zeile, dass ein Balkendiagramm ausgegeben werden soll, wobei mit den Unterbefehlen width=1 und color=“white” festgelegt wird, dass zwischen den einzelnen Bereichen eine weiße Linie gezeichnet werden soll. Der nachfolgende Befehl coord_polar() definiert, dass in diesem Fall kein Balkendiagramm, sondern ein Kreisdiagramm erzeugt werden soll. Die erste Angabe – in diesem Fall “y” – legt dabei fest, welche Information dargestellt werden soll, während über den Unterbefehl start= definiert wird, wie das Kreisdiagramm ausgerichtet ist. Schließlich wird mit theme_void() festgelegt, dass kein Hintergrund und keine Beschriftungen dargestellt werden.
Um die Farben anzupassen und Beschriftungen direkt zu den zugehörigen Kreisabschnitten hinzuzufügen sind die folgenden Modifikationen erforderlich:
ggplot(data_plot_kurse, aes(x="", y=freq, fill=FSW312)) +
geom_bar(stat="identity", width=1, color="white", position = position_stack(reverse = TRUE)) +
scale_fill_brewer(palette = "Blues", direction = -1) +
coord_polar("y", start=0) +
theme_void() +
theme(axis.text.x=element_text(colour='black')) +
scale_y_continuous(breaks=cumsum(data_plot_kurse$freq) - data_plot_kurse$freq / 2, labels=data_plot_kurse$FSW312_labels)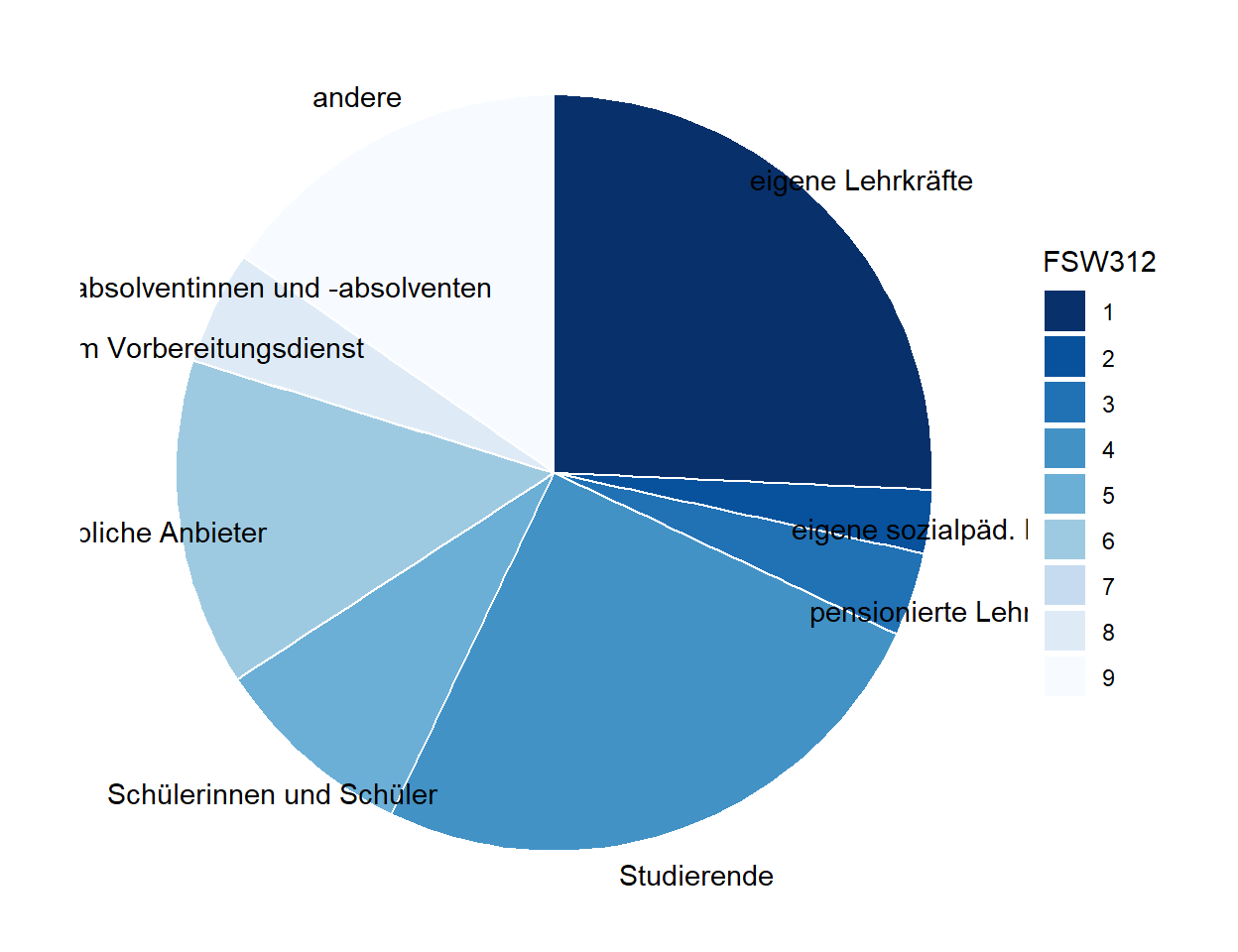
Zunächst wird im Befehl geom_bar() über den Unterbefehl position = position_stack(reverse = TRUE) die Reihenfolge der Kreisabschnitte umgehkert, sodass diese im Uhrzeigersinn dargestellt werden. Der Befehl scale_fill_brewer(palette = “Blues,” direction = -1) definiert anschließend, dass die blaue Farbpalette in umgekehrter Reihenfolge auf die Abbildung angewandt werden soll. Die Spezifikation im Befehl themes() ermöglicht die Beschriftung der Labels in schwarzer Textfarbe. Der Inhalt der Labels sowie deren Position werden schließlich im Befehl scale_y_continuous() definiert. Während im Unterbefehl labels= die Quelle der Beschriftung definiert wird – wichtig ist hier die Angabe der Variable mit Spezifikation des Datenframes – wird im Unterbefehl breaks= deren Position – hier in der Mitte des jeweiligen Kreissegments – festgelegt.
Da nun die Werte in der Abbildung beschriftet sind, kann die zugehörige Legende entfernt werden. Dies ist möglich über den Unterbefehl legend.position = “none” im Befehl theme(). Gleichzeitig lassen sich in den Labels über die Verkettung von Befehlen auch noch die Prozentangaben ergänzen. Der Zeilenumbruch zwischen der Gruppenbezeichnung und dem zugehörigen Anteilswert erfolgt hier über den Unterbefehl sep = “\n”.
ggplot(data_plot_kurse, aes(x="", y=freq, fill=FSW312)) +
geom_bar(stat="identity", width=1, color="white", position = position_stack(reverse = TRUE)) +
scale_fill_brewer(palette = "Blues", direction = -1) +
coord_polar("y", start=0) +
theme_void() +
theme(axis.text.x=element_text(colour='black'), legend.position = "none") +
scale_y_continuous(breaks=cumsum(data_plot_kurse$freq) - data_plot_kurse$freq / 2, labels=paste(data_plot_kurse$FSW312_labels, percent(data_plot_kurse$freq, accuracy = .1), sep= "\n"))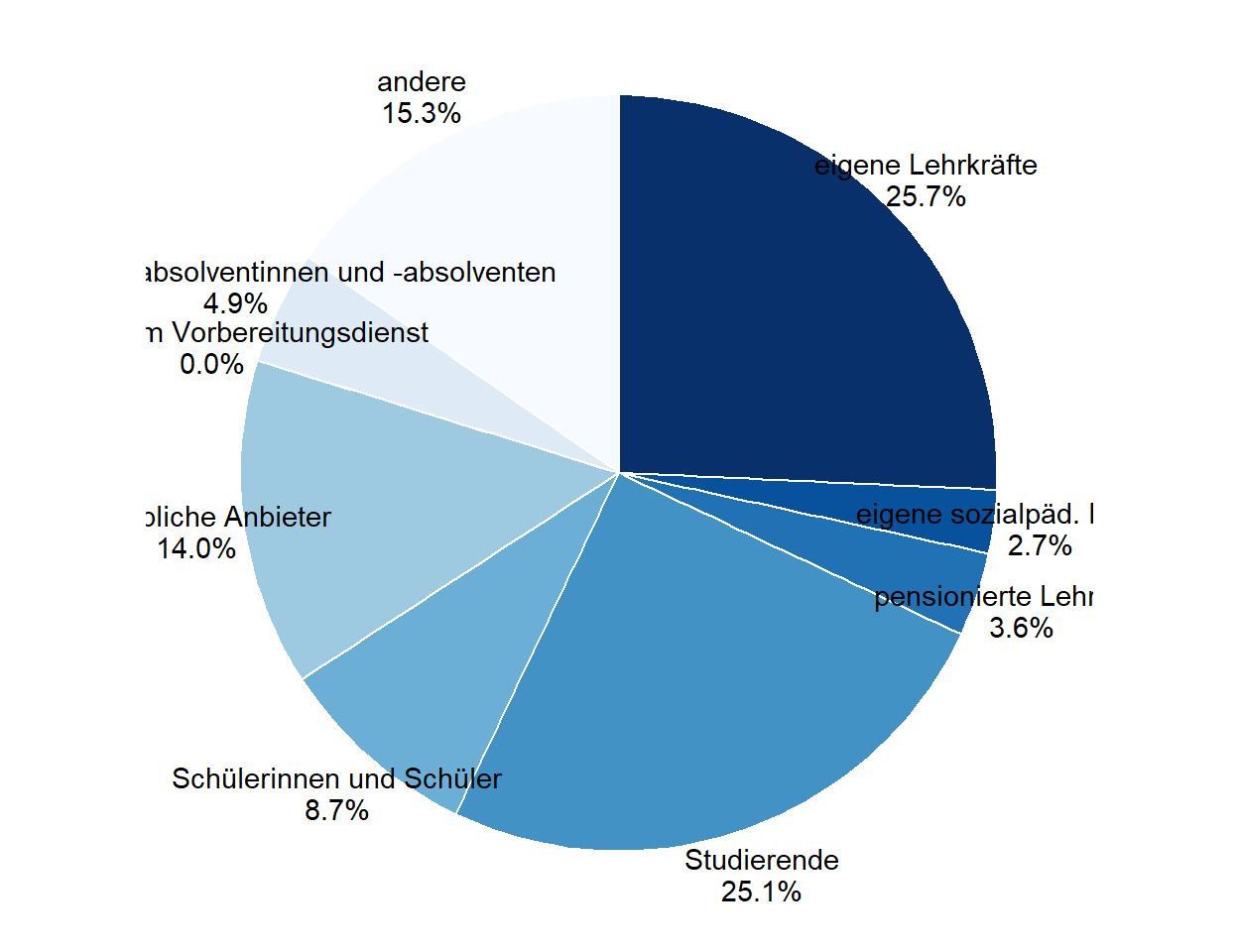
Sollte diese Darstellung noch nicht den Zielvorstellungen entsprechen, so ermöglicht das Paket ggrepel (Slowikowski 2021) das Hinzufügen von Beschriftungen in Kästchen, welche den Kreissegmenten über Linien zugeordnet werden. Dazu ist lediglich festzulegen, welche Daten in diesen Kästchen dargestellt werden. Entsprechend der zuvor dargestellten Daten, sind dies im nachfolgenden Beispiel die Gruppenbezeichnung und der zugehörige Anteil. Dazu ist zunächst der Befehl scale_y_continuous() aus dem obigen Beispiel zu löschen, da ansonsten eine Verdopplung der Beschriftung erfolgt. Die entsprechednen Informationen tauchen jedoch nun im Befehl geom_label_repel() auf. So wird hier spezifiziert, welche Daten verwendet werden sollen (Unterbefehl data=) und welche Informationen dargestellt werden sollen (Unterbefehl aes()). Ebenso werden die Größe (Unterbefehl size=), die Position (Unterbefehl nudge_x=) sowie die Füllung der Kästchen (Unterbefehl fill=) – in diesem Fall halbstransparentes Weiß – bestimmt.
ggplot(data_plot_kurse, aes(x="", y=freq, fill=FSW312)) +
geom_bar(stat="identity", width=1, color="white", position = position_stack(reverse = TRUE)) +
scale_fill_brewer(palette = "Blues", direction = -1) +
coord_polar("y", start=0) +
geom_label_repel(data = data_plot_kurse,
aes(y = cumsum(freq) - freq / 2, label = paste(FSW312_labels, percent(freq, accuracy = .1), sep = "\n")),
size = 4, nudge_x = 1, show.legend = FALSE,
fill = alpha(c("white"),0.5)) +
theme_void() +
theme(legend.position = "none")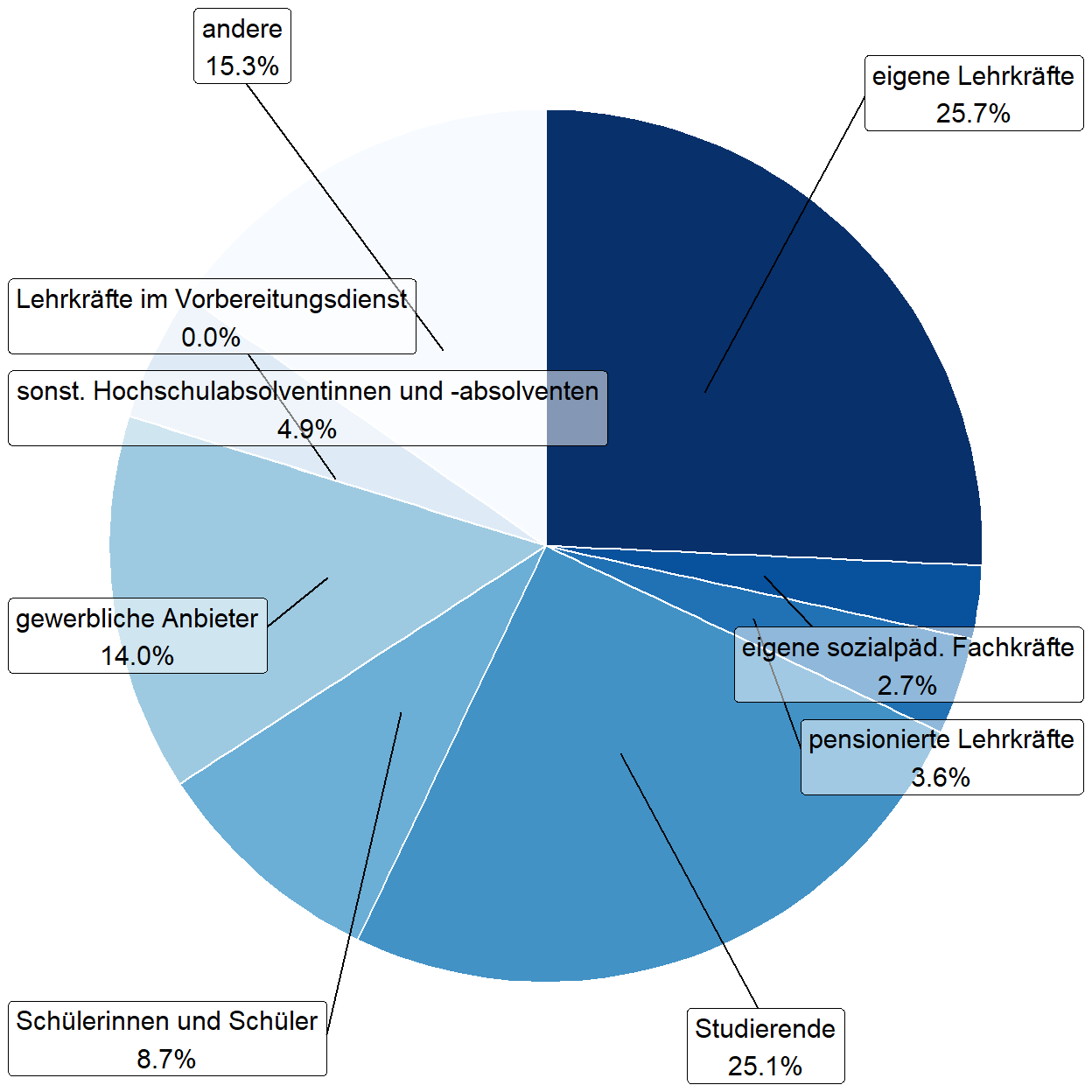
6.6 Erstellung eines Spinnennetzdiagramms20
Ähnlich wie ein Kreisdiagramm kann ein Spinnennetzdiagramm oder Radardiagramm zur Visualisierung von Werten in einer Kreisform verwendet werden. Aufgrund dieser Ähnlichkeit wird für das folgende Beispiel der zuvor generierte Datenframe data_plot_kurse über die Durchführung der Lernförderkurse verwendet. Für die Darstellung des Spinnennetzdiagramms mittels des fmsb Pakets (Nakazawa 2021) wird ein Datenframe im wide Format benötigt. Dazu wird erneut der Befehl pivot_wider() genutzt, wobei die Spaltennamen aus den Gruppenbezeichungen (FSW312_labels) und die Werte aus den Häufigkeiten (freq) übernommen werden.
data_plot_kurse_wide <- pivot_wider(select(data_plot_kurse, FSW312_labels, freq), names_from = FSW312_labels, values_from = freq)Anschließend müssen dem Datenframe zwei zusätzliche Zeilen hinzugefügt werden, welche das Minimum und das Maximum des jeweiligen Bereichs ausweisen. Diese zusätzliche Information wird vom hier verwendeten fmsb Paket (Nakazawa 2021) benötigt, um die Achsen entsprechend skalieren zu können. Die Vorgabe des Pakets ist, dass das Maximum in der ersten Zeile und das Minimum in der zweiten Zeile des Datenframes ausgegeben werden. Die anzuzeigenden Werte sollen in den dann nachfolgenden Zeilen ausgewiesen werden. Diese Anforderung lässt sich folgendermaßen umsetzen:
data_plot_kurse_wide <- rbind(rep(1,9), rep(0,9), data_plot_kurse_wide)Mit dem Befehl rbind() werden die in der Klammer aufgeführten Objekte miteinander kombiniert. Das Maximum aller Variablen wird hier über den Befehl rep(1,9) generiert, welcher die Replikation von Vektoren und Listen ermöglicht – in diesem Fall wird der Wert 1 neunmal kopiert. Entsprechend wird über den Befehl rep(0,9) der Wert 0 neunmal kopiert, sodass anschließend alle Variablen mit dem jeweiligen Minimum versehen sind.21
Der auf diese Weise ergänzte Datenframe kann genutzt werden um ein Spinnennetzdiagramm zu erzeugen:
radarchart(data_plot_kurse_wide)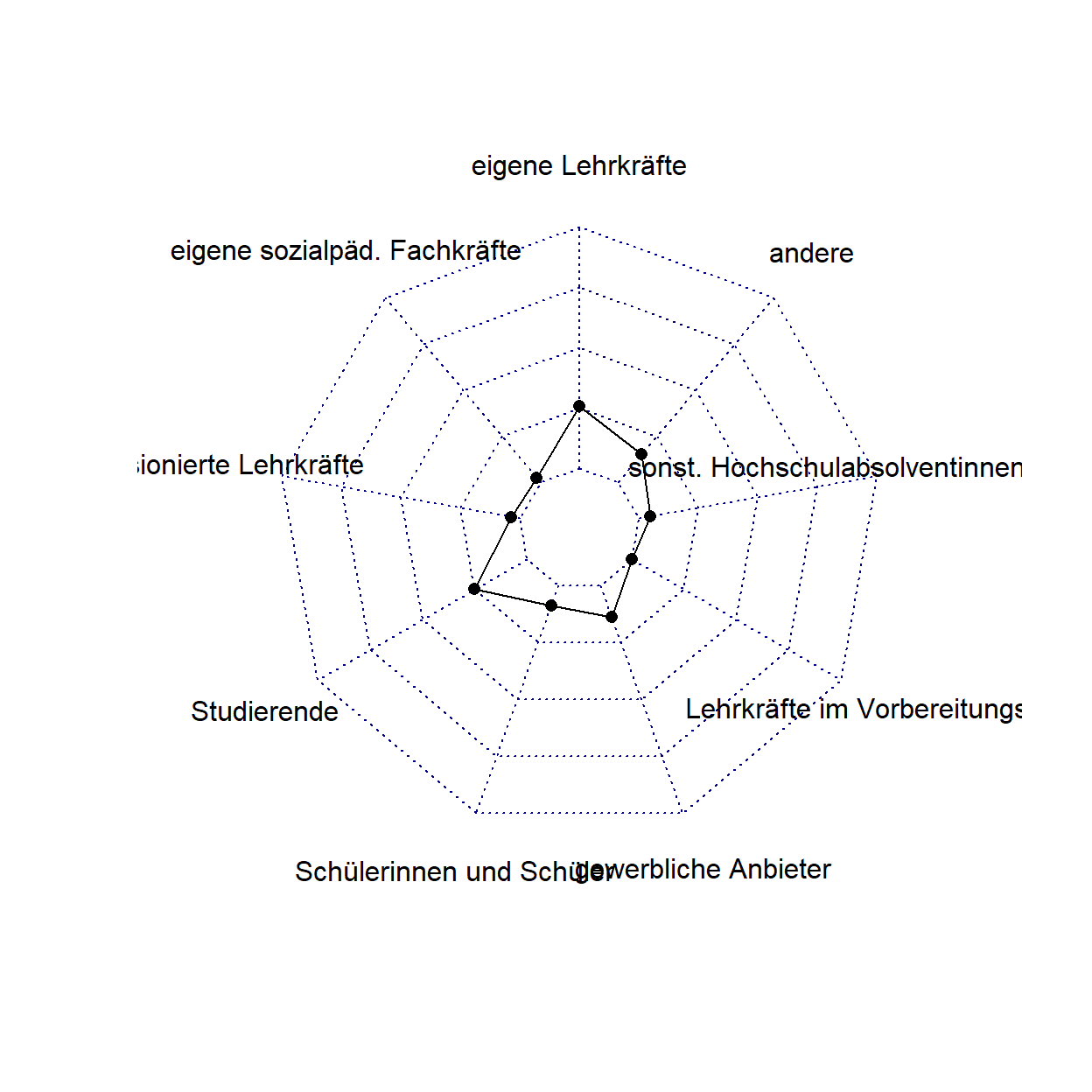
Dieses Spinnennetzdiagramm kann durch weitere Vorgaben angepasst werden. So können mit den folgenden Unterbefehlen beispielsweise die Achsenbeschriftungen (axistype=), die Farben der darzustellenden Daten (pcol=) inklusive deren Füllfarbe (pfcol=) und der Linienstärke (plwd=) festgelegt werden. Darüber hinaus lässt sich die Darstellung des Spinnennetzes anpassen und zwar hinsichtlich der Farbe der Linien (cglcol=), des Linientyps (cglty=), der Farbe der Labels (axislabcol=), der Achsenspannweite (caxislabels=) und der Linienbreite (cglwd=). Abschließend wird die Größe der Wertebeschriftungen angepasst (vlcex=).22
radarchart(data_plot_kurse_wide,
axistype=1,
pcol="#003063" , pfcol=alpha("#003063",0.5), plwd=4,
cglcol="#e3e3e3", cglty=1, axislabcol="#e3e3e3", caxislabels=seq(0,100,25), cglwd=0.8,
vlcex=0.8)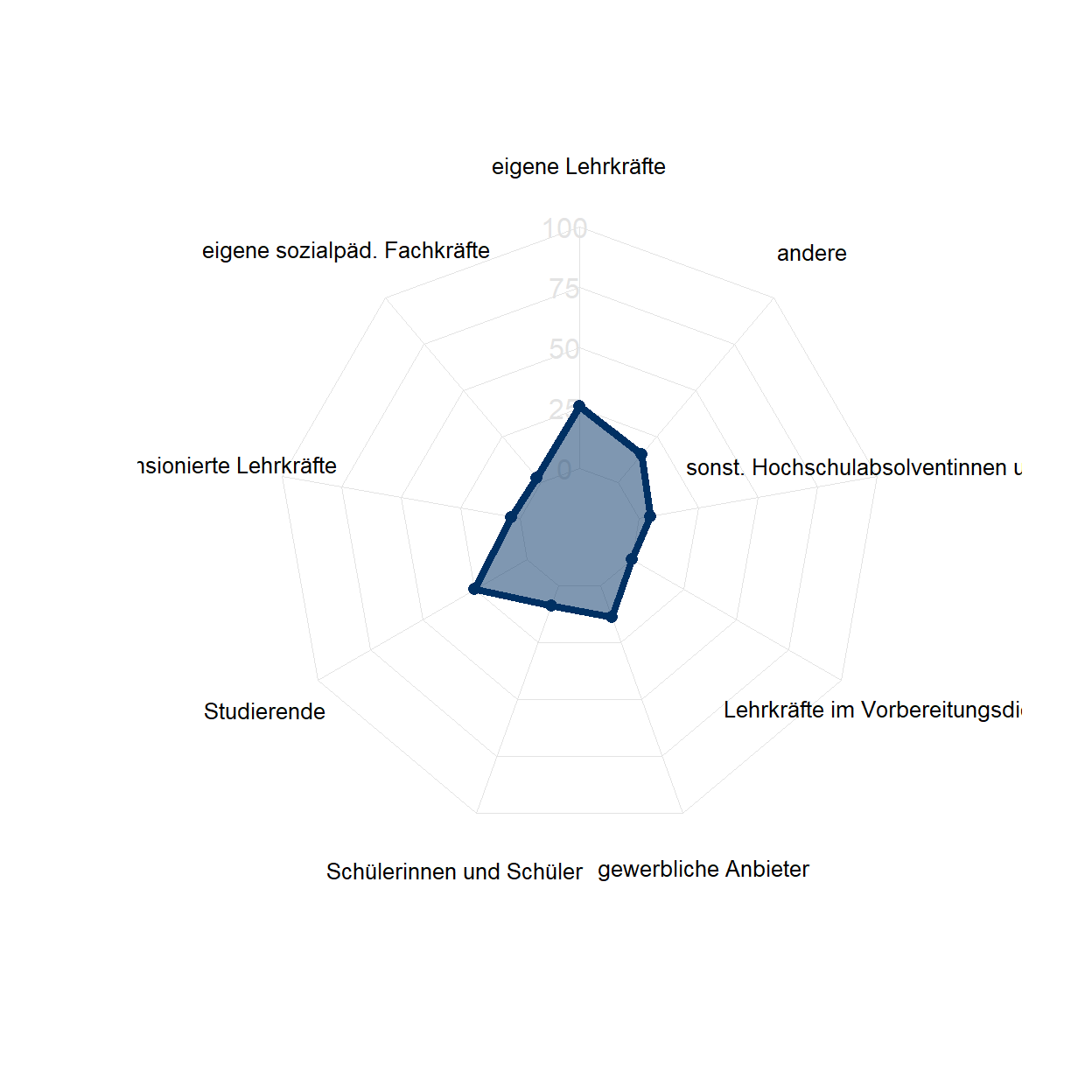
References
Dieser Schritt kann auch bereits in den vorherigen Schritt zur Erzeugung des Datenframes integriert werden. Aus didaktischen Gründen erfolgt hier eine Trennung der Schritte.↩︎
Eine Übersicht über die modifizierbaren Komponenten eines Themes findet sich hier: https://ggplot2.tidyverse.org/reference/theme.html↩︎
Auch hierfür gibt es alternative Wege. So könnte der Titel auch im Befehl labs() über den Unterbefehl title = hinzugefügt werden.↩︎
Dieses Beispiel basiert auf adaptiertem Code aus der R Graph Gallery (https://www.r-graph-gallery.com/142-basic-radar-chart.html).↩︎
Die Werte 0 und 1 werden verwendet, da es sich bei den auszuweisenden Werten um Anteile handelt.↩︎
Weitere Anpassungsmöglichkeiten sind in der Dokumentation des Pakets oder auf folgender Website aufgelistet: https://rdrr.io/cran/fmsb/man/radarchart.html↩︎